I have the following Pandas DataFrame:
import pandas as pd
import numpy as np
df = pd.DataFrame({'id': [1, 2, 3, 4], 'type': ['a,b,c,d', 'b,d', 'c,e', np.nan]})

I need to split the type column based on the commma delimiter and pivot the values into multiple columns to get this
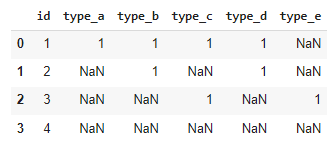
I looked at Pandas documentation for pivot() and also searched stackoverflow. I did not find anything that seems to achieve (directly or indirectly) what I need to do here. Any suggestions?
CodePudding user response:
You could use str.get_dummies to get the dummy variables; then join back to df:
out = df[['id']].join(df['type'].str.get_dummies(sep=',').add_prefix('type_').replace(0, float('nan')))
Output:
id type_a type_b type_c type_d type_e
0 1 1.0 1.0 1.0 1.0 NaN
1 2 NaN 1.0 NaN 1.0 NaN
2 3 NaN NaN 1.0 NaN 1.0
3 4 NaN NaN NaN NaN NaN