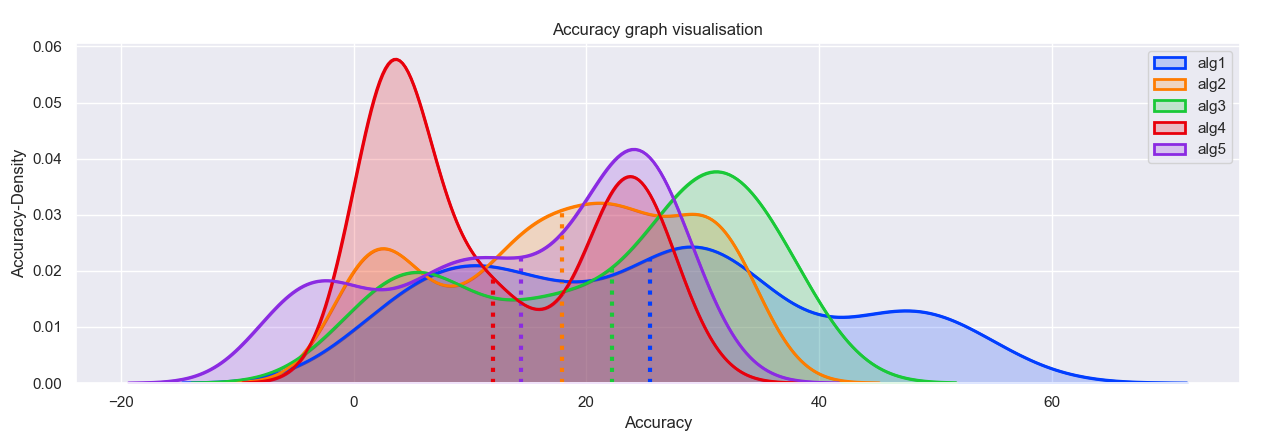
I have a problem statement to draw graphs on 5 CSV files of algorithm and compare the better algorithm among them
The csv file contains only floating point numbers of 100 rows * 4 columns I have plotted the kdeplot comparing the 1st column of 5 csv files
so I code the problem like this:
from cProfile import label
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
plt.style.use("fivethirtyeight")
sns.set_theme()
sns.color_palette("bright")
data1 = pd.read_csv("D:/C /Programs/Python/Input/appendicitis/alg1/AverageIter1000.csv", on_bad_lines='skip', nrows= 100 , usecols=[0,1,2,3] , header = None)
data2 = pd.read_csv("D:/C /Programs/Python/Input/appendicitis/alg2/AverageIter1000.csv", on_bad_lines='skip', nrows= 100 , usecols=[0,1,2,3] , header = None)
data3 = pd.read_csv("D:/C /Programs/Python/Input/appendicitis/alg3/AverageIter1000.csv", on_bad_lines='skip', nrows= 100 , usecols=[0,1,2,3] , header = None)
data4 = pd.read_csv("D:/C /Programs/Python/Input/appendicitis/alg4/AverageIter1000.csv", on_bad_lines='skip', nrows= 100 , usecols=[0,1,2,3] , header = None)
data5 = pd.read_csv("D:/C /Programs/Python/Input/appendicitis/alg5/AverageIter1000.csv", on_bad_lines='skip', nrows= 100 , usecols=[0,1,2,3] , header = None)
sns.kdeplot(np.array(data1[0]), shade = True, linewidth = 2, label = 'arg1')
sns.kdeplot(np.array(data2[0]), shade = True, linewidth = 2, label = 'arg2')
sns.kdeplot(np.array(data3[0]), shade = True, linewidth = 2, label = 'arg3')
sns.kdeplot(np.array(data4[0]), shade = True, linewidth = 2, label = 'arg4')
sns.kdeplot(np.array(data5[0]), shade = True, linewidth = 2, label = 'arg5')
plt.xlabel("Accuracy")
plt.ylabel("Accuracy-Density")
plt.title("Accuracy graph visualisation")
plt.legend()
plt.show()
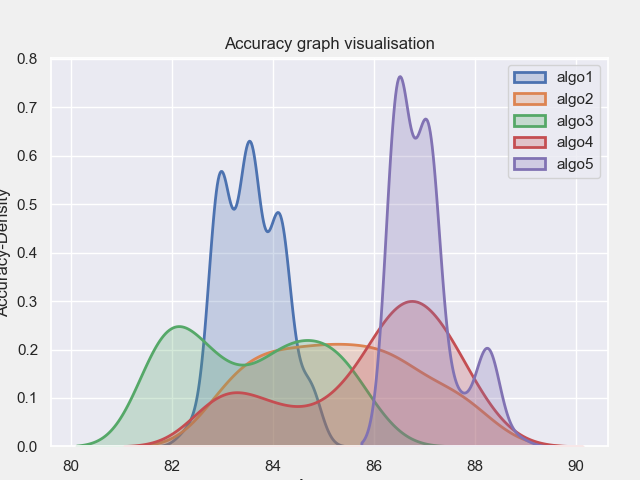
it does the work in plotting the graphs but what mainly I need is to highlight the average point in each graph. So how to do this please help me
CodePudding user response:
You could apply the approach of