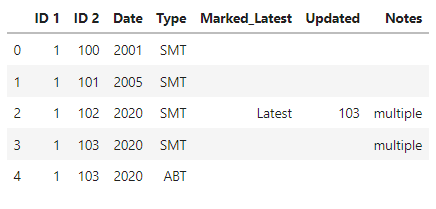
I am working with the following table:
------ ------ ------ ------ --------------- --------- -------
| ID 1 | ID 2 | Date | Type | Marked_Latest | Updated | Notes |
------ ------ ------ ------ --------------- --------- -------
| 1 | 100 | 2001 | SMT | | | |
| 1 | 101 | 2005 | SMT | | | |
| 1 | 102 | 2020 | SMT | Latest | | |
| 1 | 103 | 2020 | SMT | | | |
| 1 | 103 | 2020 | ABT | | | |
| 2 | 201 | 2009 | CMT | Latest | | |
| 2 | 202 | 2022 | SMT | | | |
| 2 | 203 | 2022 | SMT | | | |
------ ------ ------ ------ --------------- --------- -------
I am trying to perform the following steps using a df.query() but since there are so many caveats I am not sure how to fit them all in.
Step 1: Only looking at Type == "SMT" or Type == "CMT", group by ID 1 and identify latest date, compare this (grouped ID 1 data) to date of Marked_Latest == "Latest (essentially, just verifying that the date is correct)
Step 2: If the date values are the same, do nothing. If different, then supply ID 2 next to original Marked_Latest == "Latest" in Updated
Step 3: If multiple Latest have the same max Date, put a note in Notes that says "multiple".
This will result in the following table:
------ ------ ------ ------ --------------- --------- ----------
| ID 1 | ID 2 | Date | Type | Marked_Latest | Updated | Notes |
------ ------ ------ ------ --------------- --------- ----------
| 1 | 100 | 2001 | SMT | | | |
| 1 | 101 | 2005 | SMT | | | |
| 1 | 102 | 2020 | SMT | Latest | | multiple |
| 1 | 103 | 2020 | SMT | | | multiple |
| 1 | 103 | 2020 | ABT | | | |
| 2 | 201 | 2009 | CMT | Latest | 203 | |
| 2 | 202 | 2022 | SMT | | | multiple |
| 2 | 203 | 2022 | SMT | | | multiple |
------ ------ ------ ------ --------------- --------- ----------
To summarize: check that the latest date is actually marked as latest date. If it is not marked as latest date, write the updated ID 2 next to the original (incorrect) latest date. And when there are multiple cases of latest date, inputting "multiple" for each ID of latest date.
I have gotten only as far as identifying the actual latest date, using
q = df.query('Type' == "SMT" or 'Type' == "CMT").groupby('ID 1').last('ID 2')
q
This will return a subset with the latest dates marked, but I am not sure how to proceed from here, i.e. how to now compare this dataframe with the date field corresponding to Marked_Latest.
All help appreciated.
CodePudding user response:
Use:
#ID from ID 1 only if match conditions
df['ID'] = df['ID 1'].where(df['Type'].isin(['SMT','CMT']))
#get last Date, ID 2 per `ID` to columns Notes, Updates
df[['Notes', 'Updated']] = df.groupby('ID')[['Date', 'ID 2']].transform('last')
#comapre latest date in Notes with original Date
m1 = df['Notes'].ne(df['Date'])
#if no match set empty string
df['Updated'] = df['Updated'].where(m1 & df['Marked_Latest'].eq('Latest'), '')
#if latest date is duplicated set value multiple
df['Notes'] = np.where(df.duplicated(['ID 1','Date'], keep=False) & ~m1, 'multiple','')
df = df.drop('ID', axis=1)
print (df)
ID 1 ID 2 Date Type Marked_Latest Updated Notes
0 1 100 2001 SMT NaN
1 1 101 2005 SMT NaN
2 1 102 2020 SMT Latest multiple
3 1 103 2020 SMT NaN multiple
4 1 103 2020 ABT NaN
5 2 201 2009 CMT Latest 203.0
6 2 202 2022 SMT NaN multiple
7 2 203 2022 SMT NaN multiple
CodePudding user response:
Try:
cols = ['ID 1', 'ID 2', 'Date', 'Type', 'Marked_Latest', 'Updated', 'Notes']
data = [[1, 100, 2001, 'SMT', '', '', ''],
[1, 101, 2005, 'SMT', '', '', ''],
[1, 102, 2020, 'SMT', 'Latest', '', ''],
[1, 103, 2020, 'SMT', '', '', ''],
[1, 103, 2020, 'ABT', '', '', '']]
df = pd.DataFrame(data, columns = cols)
temp = df[(df['Type'] == "SMT")|(df['Type'] == "CMT")]
new = temp.groupby('ID 1')['ID 2'].last().values[0]
latest = temp[temp['Marked_Latest'] == 'Latest']
nind = temp[temp['ID 2'] == new].index
if new != latest['ID 2'].values[0]:
df.loc[latest.index,'Updated']=new
df.loc[latest.index, 'Notes'] = 'multiple'
df.loc[nind, 'Notes'] = 'multiple'
Output: