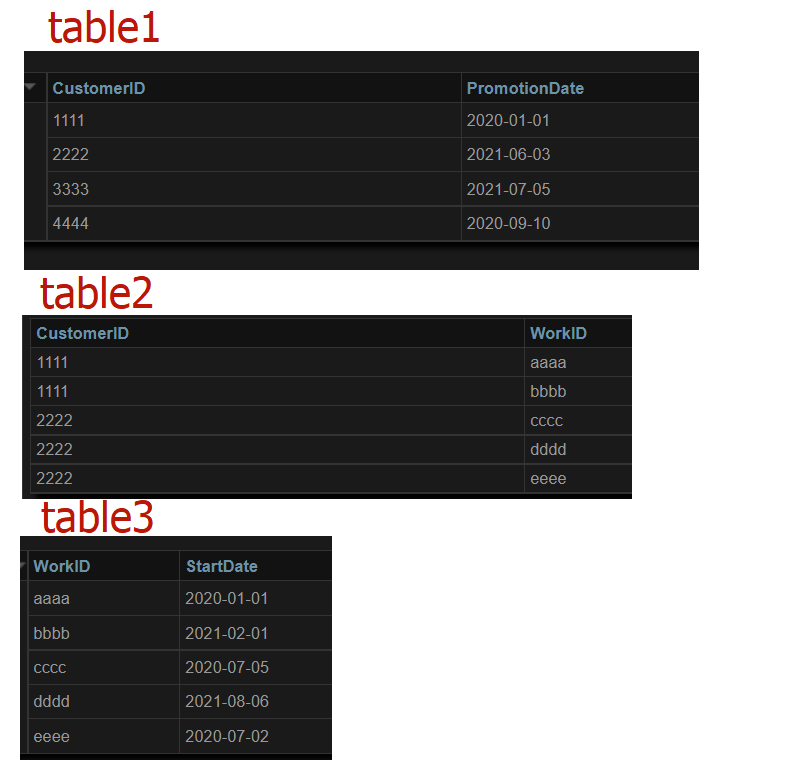
I have 3 tables:
CustomerID | PromotionDate
1111 | 01-01-2020
2222 | 03-06-2021
3333 | 05-07-2021
4444 | 09-10-2020
CustomerID | WorkID
1111 | aaaa
1111 | bbbb
2222 | cccc
2222 | dddd
2222 | eeee
WorkID | StartDate
aaaa | 01-01-2020
bbbb | 01-02-2021
cccc | 05-07-2020
dddd | 06-08-2021
eeee | 03-07-2022
I want to find the count of WorkIDs for each CustomerIDs where StartDate >= PromotionDate for that CustomerID.
So the result for the above sample should be:
CustomerID | Count
1111 | 2
2222 | 2
3333 | 0
4444 | 0
How to achieve this?
CodePudding user response:
Replace the table names with the real names and that should work as you except.
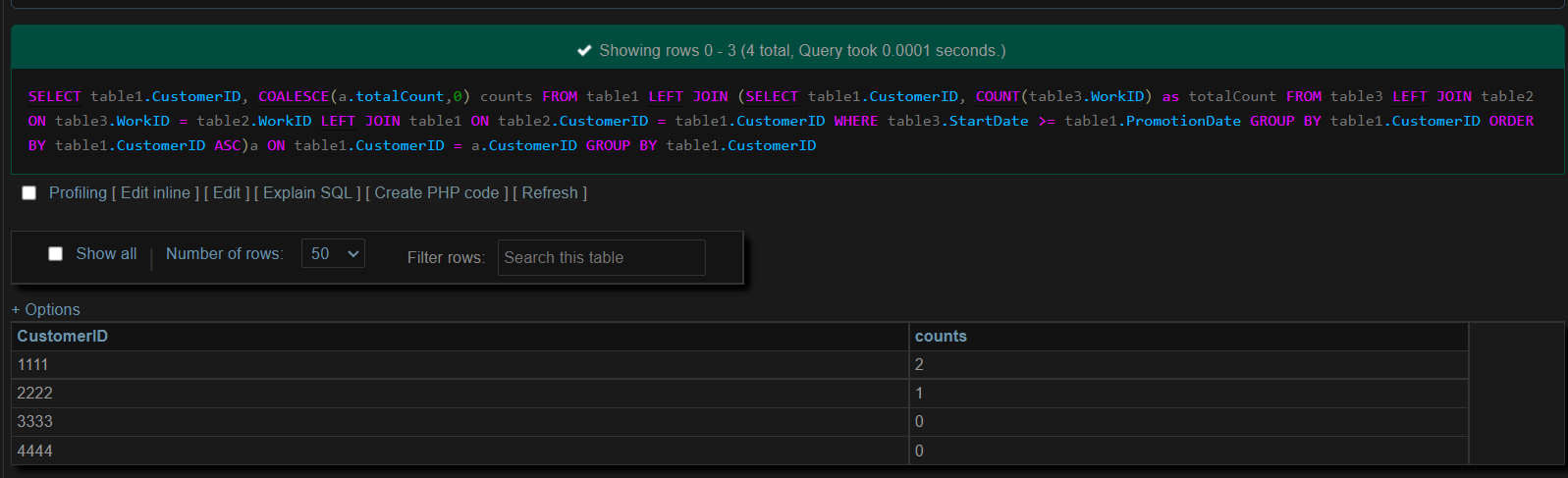
SELECT table1.CustomerID, COALESCE(a.totalCount,0) counts FROM table1
LEFT JOIN (SELECT table1.CustomerID, COUNT(table3.WorkID) as totalCount
FROM table3
LEFT JOIN table2 ON table3.WorkID = table2.WorkID
LEFT JOIN table1 ON table2.CustomerID = table1.CustomerID
WHERE table3.StartDate >= table1.PromotionDate
GROUP BY table1.CustomerID ORDER BY table1.CustomerID ASC)a ON table1.CustomerID = a.CustomerID GROUP BY table1.CustomerID
I am using aggregation function called COUNT() to calculate the number of similar occurrences of the same Customer. GROUP BY to span similar records into one and in order to use the COUNT() function. ORDER BY is used to sort it by the CustomerID
My data:
Results:
CodePudding user response:
Disclaimer: I don't use PostgreSQL so there may be a better option. However a general approach is to use conditional SUM() to count the number of records where StartDate >= PromotionDate:
SELECT t1.CustomerId
, SUM( CASE WHEN t3.StartDate >= t1.PromotionDate THEN 1 ELSE 0 END ) AS "Count"
FROM Table1 t1
LEFT JOIN Table2 t2 ON t1.CustomerID = t2.CustomerID
LEFT JOIN Table3 t3 ON t2.WorkId = t3.WorkId
GROUP BY t1.CustomerId
Results:
| customerid | totalcount |
|---|---|
| 1111 | 2 |
| 2222 | 2 |
| 3333 | 0 |
| 4444 | 0 |
db<>fiddle here
CodePudding user response:
This should work in Redshift:
SELECT p.customerid
, count(s.startdate >= p.promotiondate OR NULL) AS total_count
FROM cust_promo p
LEFT JOIN cust_work w ON w.customerid = p.customerid
LEFT JOIN work_start s ON s.workid = w.workid
GROUP BY p.customerid;
db<>fiddle here
Assuming workid is UNIQUE in table work_start (as seems reasonable).
The aggregate FILTER clause performs better in modern Postgres. But Redshift doesn't keep up since its fork long ago:
SELECT p.customerid
, count(*) FILTER (WHERE s.startdate >= p.promotiondate) AS total_count
FROM cust_promo p
LEFT JOIN cust_work w ON w.customerid = p.customerid
LEFT JOIN work_start s ON s.workid = w.workid
GROUP BY p.customerid;
See: