II currently have a very large .csv with 2 million rows. I've read in the csv and only have 2 columns, number and timestamp (in unix). My goal is to grab the last and largest number for each day (eg. 1/1/2021, 1/2/2021, etc.)
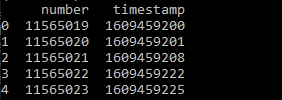
I have converted unix to datetime and used df.groupby('timestamp').tail(1) but am still not able to return the last row per day. Am I using the groupby wrong?
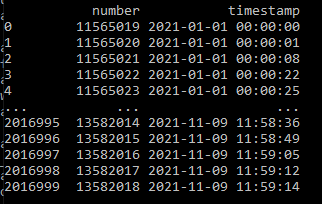
import pandas as pd
def main():
df = pd.read_csv('blocks.csv', usecols=['number', 'timestamp'])
print(df.head())
df['timestamp'] = pd.to_datetime(df['timestamp'],unit='s')
x = df.groupby('timestamp').tail(1)
print(x)
if __name__ == '__main__':
main()
Desired Output:
number timestamp
11,509,218 2021-01-01
11,629,315 2021-01-02
11,782,116 2021-01-03
12,321,123 2021-01-04
...
CodePudding user response:
The "problem" lies in the grouper, use .dt.date for correct grouping (assuming your data is already sorted):
x = df.groupby(df['timestamp'].dt.date).tail(1)
print(x)
CodePudding user response:
Doesn't seem like you're specifying the aggregation function, nor the aggregation frequency (hour, day, minute?) My take would be something along the lines of
df.resample("D", on="timestamp").max()
There's a couple of ways to group by time, alternatively
df.groupby(pd.Grouper(key='timestamp', axis=0,
freq='D', sort=True)).max()
Regards