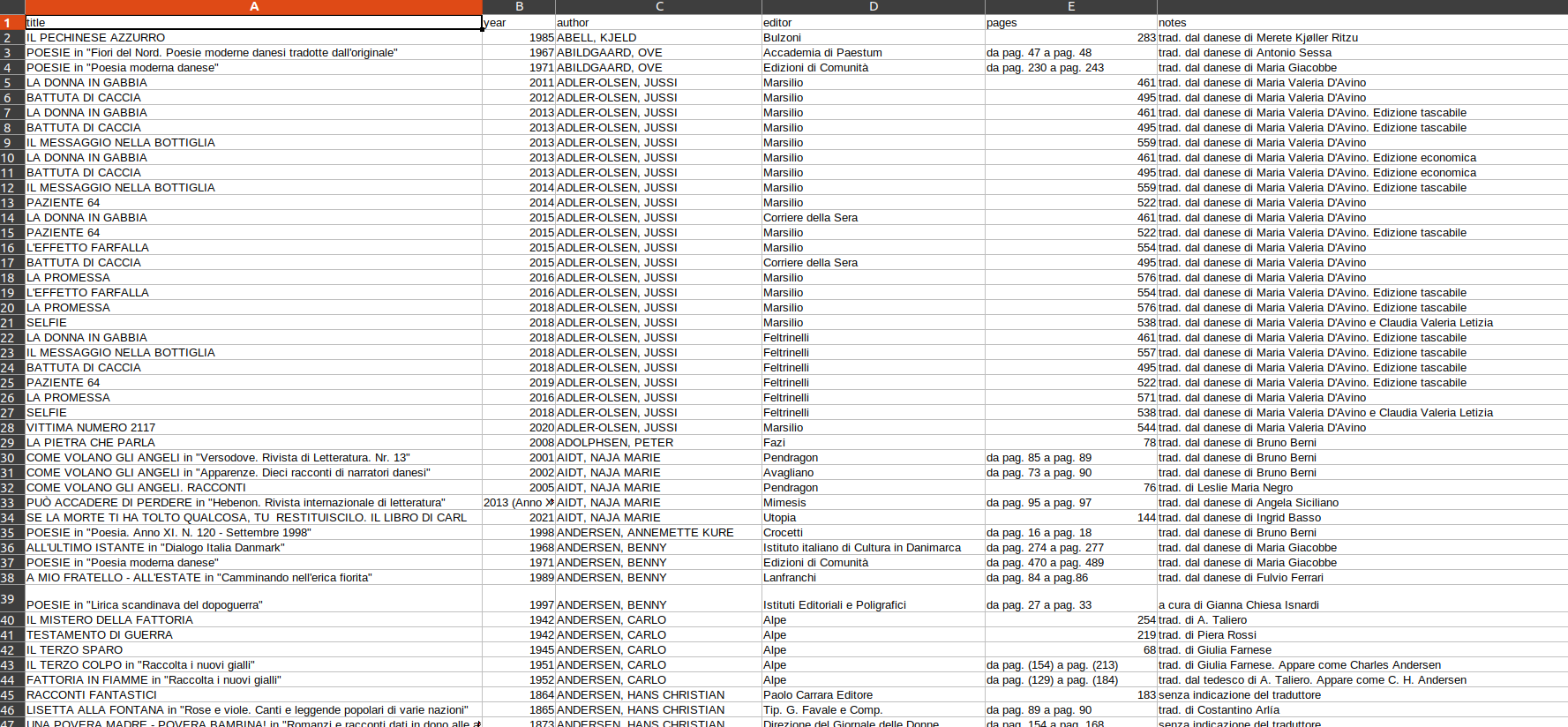
I'm using Beautiful Soup to put in a excel table some infos from a website.

The bold titles are shown in the head columns while the text after the colon appear in the rows.
What I'm doing is finding the text and searching for next_sibling -->
book_year = sibling.pre.find('b',text='Anno:').next_sibling.get_text().strip()
The problem is that in some cases the text after colon, is split in different #text part. So if I use the next_sibling, it'll get only a partial info.
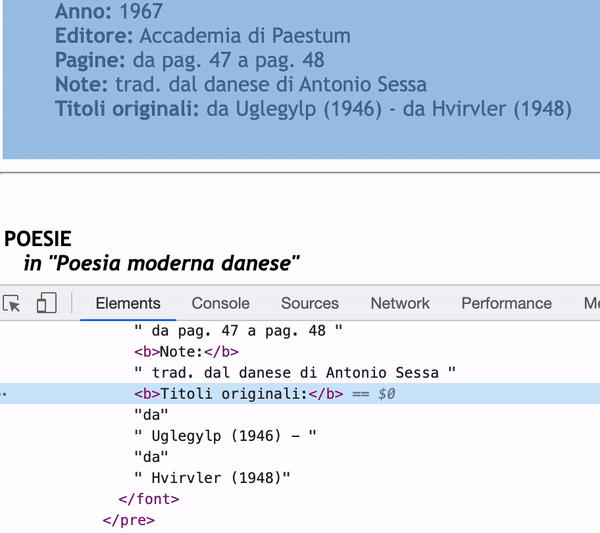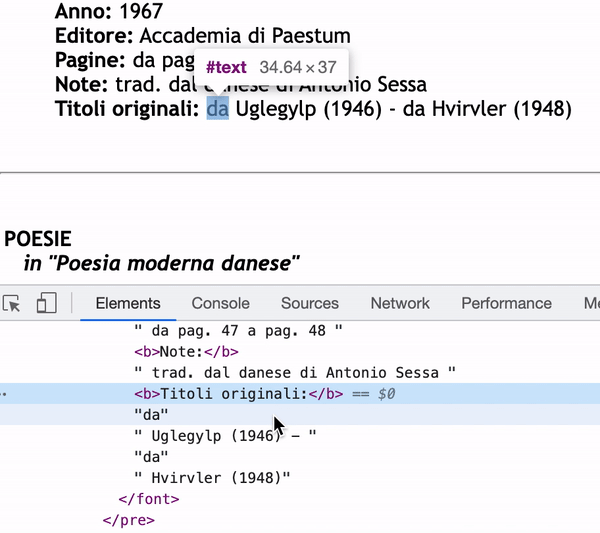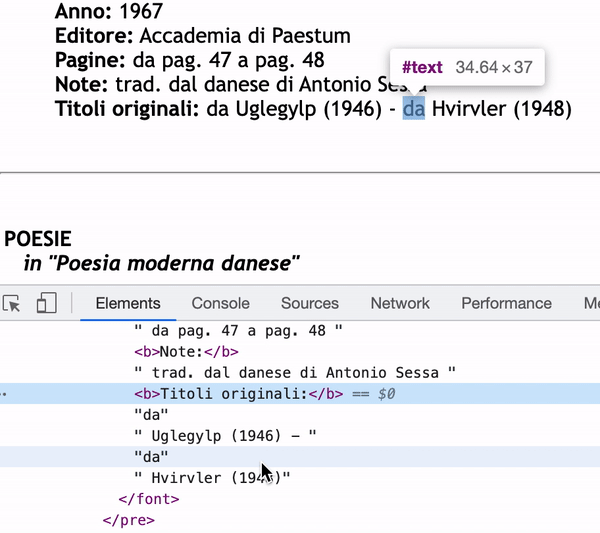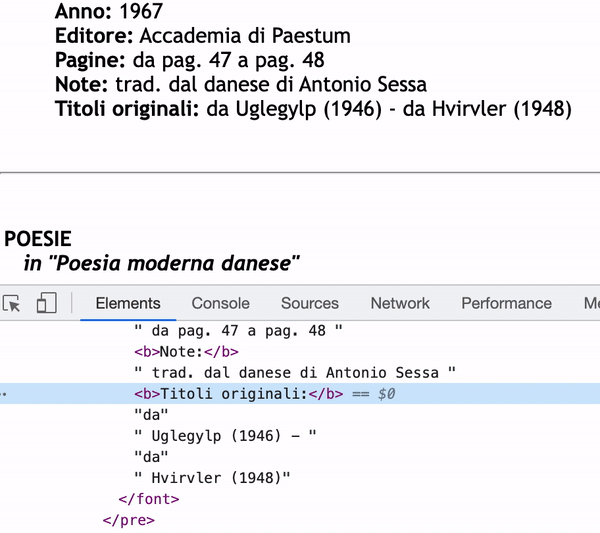
As you can see in the inspector, the content of Titoli originali: will only be "da" if I use next_sibling.
Is there a way to unify all those #text parts? How would you approach this problem? Thank you
UPDATES:
This is the website I'm scraping from -->