I want to make a beta calculation in my dataframe, where beta = Σ(daily returns - mean daily return) * (daily market returns - mean market return) / Σ (daily market returns - mean market return)**2
But I want my beta calculation to apply to specific firms. In my dataframe, each firm as an ID code number (specified in column 1), and I want each ID code to be associated with its unique beta.
I tried groupby, loc and for loop, but it seems to always return an error since the beta calculation is quite long and requires many parenthesis when inserted.
Any idea how to solve this problem? Thank you!
Dataframe:
index ID price daily_return mean_daily_return_per_ID daily_market_return mean_daily_market_return date
0 1 27.50 0.008 0.0085 0.0023 0.03345 01-12-2012
1 2 33.75 0.0745 0.0745 0.00458 0.0895 06-12-2012
2 3 29,20 0.00006 0.00006 0.0582 0.0045 01-05-2013
3 4 20.54 0.00486 0.005125 0.0009 0.0006 27-11-2013
4 1 21.50 0.009 0.0085 0.0846 0.04345 04-05-2014
5 4 22.75 0.00539 0.005125 0.0003 0.0006
CodePudding user response:
Maybe you can start like this?
id_list = list(set(df["ID"].values.tolist()))
for firm_id in id_list:
new_df = df.loc[df["ID"] == firm_id]
CodePudding user response:
I assume the following form of your equation is what you intended.
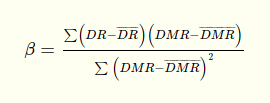
Then the following will work.
import pandas as pd
import numpy as np
# beta_data.csv is a csv version of the sample data frame you
# provided.
df = pd.read_csv('./beta_data.csv')
def beta(daily_return, daily_market_return):
"""
Returns the beta calculation for two pandas columns of equal length.
Will return NaN for columns that have just one row each. Adjust
this function to account for groups that have only a single value.
"""
mean_daily_return = np.sum(daily_return) / len(daily_return)
mean_daily_market_return = np.sum(daily_market_return) / len(daily_market_return)
num = np.sum((daily_return - mean_daily_return) * (daily_market_return - mean_daily_market_return))
denom = np.sum((daily_market_return - mean_daily_market_return)**2)
return num / denom
# groupby the column ID. Then 'apply' the function we created above
# columnwise to the two desired columns
betas = df.groupby('ID')['daily_return',
'daily_market_return'].apply(lambda x:
beta(x['daily_return'],
x['daily_market_return']))
print(betas)
The output is
ID
1 0.012151
2 NaN
3 NaN
4 -0.883333
dtype: float64
For IDs 2 and 3 we get NaN because they only have a single row. You will have to fix the above function to work in the corner cases.