I have a raw table like below:
| Object | state | duration_hours | interval_hours |
|---|---|---|---|
| A | 1 | 0.06 | 0 |
| A | 1 | 0.87 | 34 |
| A | 1 | 1.5 | 80 |
| A | 2 | 18 | 0 |
| B | 1 | 7 | 0 |
| C | 1 | 0.3 | 0 |
| C | 2 | 3 | 0 |
| C | 2 | 4 | 12 |
Tables Schema:
- Object: Car Object
- State: Is it Scheduled or Unscheduled maintenance(1- Scheduled, 2- Unscheduled)
- duration_hours: How long did the scheduled or unscheduled maintained take.
- interval_hours: How long was the difference between first and next maintenance.(First interval for each state of object will always be 0)
Question
How can I:
- Create bins per object and state for duration_hours and interval_hours
- Calculate samples and probability falling in a bin per object and state.
Expected Output:
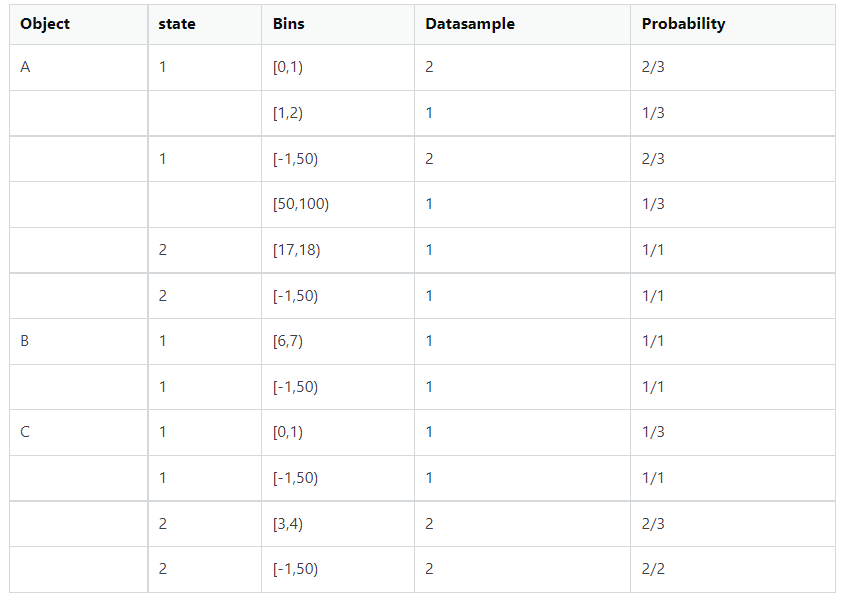 Explanation of the output table:
Explanation of the output table:
Size, Min, Max of the bin is configurable.
Each Object has State, Bins , Data sample and probability.
For each state, we have bins formed out of duration_hours and interval_hours.
Example: For Object A, State 1, we have:
a. Two bins for duration_hours and Two bins for interval_hours.
b. As there are 2 data samples between [0,1) for duration_hours, we have 2 data samples and (2/3)= 0.67 probability, similarly for interval hours, we have 2 data samples between [-1,50), we have 2 data_sample output and prob = 2/3.
Any help is sincerely appreciated.
CodePudding user response:
I'm not sure this is exactly what you want, but maybe you could use parts of it.
Provided your base dataframe is named df, you can start with using pd.cut() to bin the columns duration_hours and interval_hours:
bins = range(int(df.duration_hours.max()) 2)
df["dur"] = pd.cut(df.duration_hours, bins, right=False)
bins = range(0, int(df.interval_hours.max()) 51, 50)
df["int"] = pd.cut(df.interval_hours, bins, right=False)
Then .melt() the result into a new dataframe df_res
df_res = df.melt(
id_vars=["Object", "state"], value_vars=["dur", "int"],
value_name="Bins", var_name="Variable",
)
and groupby() and .sum() over most of it to get the Sample column
group = ["Object", "state", "Variable", "Bins"]
df_res = (
df_res[group].assign(Sample=1).groupby(group, observed=True).sum()
)
and use it to build the Prob column (by .groupby()-transform().sum() over the first three index levels):
df_res["Prob"] = (
df_res.Sample / df_res.groupby(level=[0, 1, 2]).Sample.transform('sum')
)
Result for
df =
Object state duration_hours interval_hours
0 A 1 0.06 0
1 A 1 0.87 34
2 A 1 1.50 80
3 A 2 18.00 0
4 B 1 7.00 0
5 C 1 0.30 0
6 C 2 3.00 0
7 C 2 4.00 12
is
Sample Prob
Object state Variable Bins
A 1 dur [0, 1) 2 0.666667
[1, 2) 1 0.333333
int [0, 50) 2 0.666667
[50, 100) 1 0.333333
2 dur [18, 19) 1 1.000000
int [0, 50) 1 1.000000
B 1 dur [7, 8) 1 1.000000
int [0, 50) 1 1.000000
C 1 dur [0, 1) 1 1.000000
int [0, 50) 1 1.000000
2 dur [3, 4) 1 0.500000
[4, 5) 1 0.500000
int [0, 50) 2 1.000000