I have a dataframe (df) with a value in column "Rating" and another value in column "600". I'd like to go through the entire df and color code the entire column called "rating" based on whether its greater or less than the value in column "600". I've been able to do this if I compare the rating column to a set value but haven't had luck iterating through every unique value in the column titles "600".
for index, row in df.iterrows():
if row[600] == float:
df.styled=df.style\
.applymap(lambda x: 'background-color: %s' % 'crimson' if row['600'] > row['Rating']
else 'background-color: %s' % 'orange' if row['600'] < row['Rating'])
I also tried this approach but no luck:
def HIGHLIGHT(row):
red = 'background-color: red;'
blue = 'background-color: blue;'
green = 'background-color: green;'
if row['600'] > row['Rating']:
return [red, blue]
elif row['600'] < row['Rating']:
return [blue, red]
else:
return [green, green]
df.style.apply(HIGHLIGHT, subset=['600', 'Rating'], axis=1)
CodePudding user response:
When I do this:
ratings = [9,8,3,5,6]
the600 = [10, 6, 5, 2, 1]
df = pd.DataFrame([ratings, the600]).T
df.columns = ['Rating', '600']
def HIGHLIGHT(row):
red = 'background-color: red;'
blue = 'background-color: blue;'
green = 'background-color: green;'
if row['600'] > row['Rating']:
return [red, blue]
elif row['600'] < row['Rating']:
return [blue, red]
else:
return [green, green]
df.style.apply(HIGHLIGHT, subset=['600', 'Rating'], axis=1)
I get this:
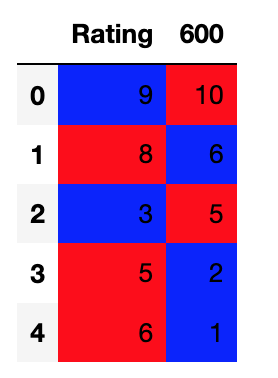
If it is not working for you I would suggest that you check the data types using df.dtypes. For example if I change one of the ratings values in the following way:
ratings = [9,8,3,"5",6]
I get this error:
TypeError: '>' not supported between instances of 'str' and 'int'
CodePudding user response:
@le-camerone, your answer helped me figure out what was happening. I had my entire table as float values and for some reasons this type of conditional formatting won't work between floats, however, after converting over to integers, I was able to get the results was expecting. This is what I included before the code to convert over from float to integer.
df['600'] =pd.to_numeric(df['600'], errors = 'coerce')
df['Rating'] =pd.to_numeric(df['Rating'], errors = 'coerce')
df = df.dropna(subset=['600'])
df = df.dropna(subset=['Rating'])
df['600'] = df['600'].astype(int)
df['Rating'] = df['Rating'].astype(int)
def HIGHLIGHT(row):
red = 'background-color: red;'
blue = 'background-color: blue;'
green = 'background-color: green;'
if row['600'] > row['Rating']:
return [red, blue]
elif row['600'] < row['Rating']:
return [blue, red]
else:
return [green, green]
df.style.apply(HIGHLIGHT, subset=['600', 'Rating'], axis=1)