I have the following dataframe:
Col
0 A,B,C
1 B,A,D
2 C
3 A,D,E,F
4 B,C,F
df = pd.DataFrame({'Col': ['A,B,C', 'B,A,D', 'C', 'A,D,E,F', 'B,C,F']})
which needs to be turned into:
A B C D E F
0 A B C
1 A B D
2 C
3 A D E F
4 B C F
CodePudding user response:
You could use str.get_dummies to get the dummy variables, then multiply with the columns:
tmp = df['Col'].str.get_dummies(sep=',')
out = tmp * tmp.columns
One-liner as suggested by @piRSquared:
out = df.Col.str.get_dummies(',').pipe(lambda d: d*[*d])
Output:
A B C D E F
0 A B C
1 A B D
2 C
3 A D E F
4 B C F
Benchmark:
On data created by duplicating the data in the OP:
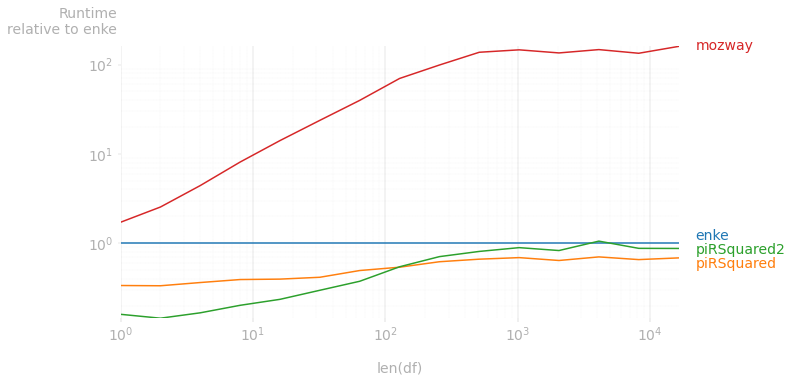
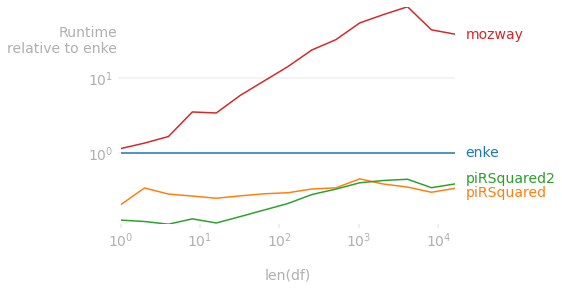
Code to reproduce the plot:
import perfplot
import pandas as pd
import numpy as np
def enke(df):
tmp = df['Col'].str.get_dummies(sep=',')
return tmp * tmp.columns
def mozway(df):
return pd.concat([pd.Series((idx:=x.split(',')), index=idx)
for x in df['Col']], axis=1).T.fillna('')
def piRSquared(df):
n = df.shape[0]
i = np.repeat(np.arange(n), df.Col.str.count(',') 1)
c, j = np.unique(df.Col.str.cat(sep=',').split(','), return_inverse=True)
m = c.shape[0]
a = np.full((n, m), '')
a[i, j] = c[j]
return pd.DataFrame(a, df.index, c)
def piRSquared2(df):
n = df.shape[0]
base = df.Col.to_numpy().astype(str)
commas = np.char.count(base, ',')
sepped = ','.join(base).split(',')
i = np.repeat(np.arange(n), commas 1)
c, j = np.unique(sepped, return_inverse=True)
m = c.shape[0]
a = np.full((n, m), '')
a[i, j] = c[j]
return pd.DataFrame(a, df.index, c)
def constructor1(n):
df = pd.DataFrame({'Col': ['A,B,C', 'B,A,D', 'C', 'A,D,E,F', 'B,C,F']})
return pd.concat([df]*n, ignore_index=True)
def constructor2(n):
uc = np.array([*ascii_uppercase])
k = [','.join(np.random.choice(uc, x, replace=False))
for x in np.random.randint(1, 10, size=n)]
return pd.DataFrame({'Col': k})
kernels = [enke, piRSquared, piRSquared2, mozway]
df = pd.DataFrame({'Col': ['A,B,C', 'B,A,D', 'C', 'A,D,E,F', 'B,C,F']})
perfplot.plot(
setup=constructor1,
kernels=kernels,
labels=[func.__name__ for func in kernels],
n_range=[2**k for k in range(15)],
xlabel='len(df)',
logx=True,
logy=True,
relative_to=0,
equality_check=pd.DataFrame.equals)
CodePudding user response:
Using pandas.concat:
pd.concat([pd.Series((idx:=x.split(',')), index=idx)
for x in df['Col']], axis=1).T
For python < 3.8:
pd.concat([pd.Series(val, index=val)
for x in df['Col']
for val in [x.split(',')]], axis=1).T
Output:
A B C D E F
0 A B C NaN NaN NaN
1 A B NaN D NaN NaN
2 NaN NaN C NaN NaN NaN
3 A NaN NaN D E F
4 NaN B C NaN NaN F
NB. add fillna('') to have empty strings for missing values
A B C D E F
0 A B C
1 A B D
2 C
3 A D E F
4 B C F
CodePudding user response:

This comes from my Project Overkill stash of tricks.
I'll use Numpy to identify where the labels are to be dropped in the 2-d array.
n = df.shape[0] # Get number of rows
base = df.Col.to_numpy().astype(str) # Turn `'Col'` to Numpy array
commas = np.char.count(base, ',') # Count commas in each row
sepped = ','.join(base).split(',') # Flat array of each element
i = np.repeat(np.arange(n), commas 1) # Row indices for flat array
# Note that I could've used `pd.factorize` here but I actually wanted
# a sorted array of labels so `np.unique` was the way to go.
# Otherwise I'd have used `j, c = pd.factorize(sepped)`
c, j = np.unique(sepped, return_inverse=True) # `j` col indices for flat array
# `c` will be the column labels
m = c.shape[0] # Get number of unique labels
a = np.full((n, m), '') # Default array of empty strings
a[i, j] = c[j] # Use row/col indices to insert
# the column labels in right spots
pd.DataFrame(a, df.index, c) # Construct new dataframe
A B C D E F
0 A B C
1 A B D
2 C
3 A D E F
4 B C F
Time Testing
The Functions
import pandas as pd
import numpy as np
from string import ascii_uppercase
def pir(s):
n = s.shape[0]
base = s.to_numpy().astype(str)
commas = np.char.count(base, ',')
sepped = ','.join(base).split(',')
i = np.repeat(np.arange(n), commas 1)
c, j = np.unique(sepped, return_inverse=True)
m = c.shape[0]
a = np.full((n, m), '')
a[i, j] = c[j]
return pd.DataFrame(a, s.index, c)
def pir2(s):
n = s.shape[0]
sepped = s.str.cat(sep=',').split(',')
commas = s.str.count(',')
i = np.repeat(np.arange(n), commas 1)
c, j = np.unique(sepped, return_inverse=True)
m = c.shape[0]
a = np.full((n, m), '')
a[i, j] = c[j]
return pd.DataFrame(a, s.index, c)
def mozway(s):
return pd.concat([
pd.Series((idx:=x.split(',')), index=idx)
for x in s
], axis=1).T.fillna('')
def enke(s):
return s.str.get_dummies(',').pipe(lambda d: d*d.columns)
The test data constructor
def constructor(n, m):
uc = np.array([*ascii_uppercase])
m = min(26, m)
k = [','.join(np.random.choice(uc, x, replace=False))
for x in np.random.randint(1, m, size=n)]
return pd.Series(k)
The results dataframe
res = pd.DataFrame(
index=['enke', 'mozway', 'pir', 'pir2'],
columns=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
dtype=float
)
Run the test
from IPython.display import clear_output
for j in res.columns:
s = constructor(j, 10)
for i in res.index:
stmt = f'{i}(s)'
setp = f'from __main__ import s, {i}'
res.at[i, j] = timeit(stmt, setp, number=50)
print(res)
clear_output(True)
Show the results
res.T.plot(loglog=True)
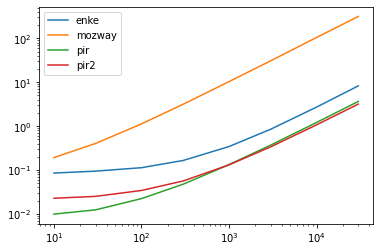
res.div(res.min()).T
enke mozway pir pir2
10 8.634105 19.416376 1.000000 2.300573
30 7.626107 32.741218 1.000000 2.028423
100 5.071308 50.539772 1.000000 1.533791
300 3.475711 66.638151 1.000000 1.184982
1000 2.616885 79.032159 1.012205 1.000000
3000 2.518983 91.521389 1.094863 1.000000
10000 2.536735 98.172680 1.131758 1.000000
30000 2.603489 99.756007 1.149734 1.000000