I'm merging some dataframes which have a time index.
import pandas pd
df1 = pd.DataFrame(['a', 'b', 'c'],
columns=pd.MultiIndex.from_product([['target'], ['key']]),
index = [
'2022-04-15 20:20:20.000000',
'2022-04-15 20:20:21.000000',
'2022-04-15 20:20:22.000000'],)
df2 = pd.DataFrame(['a2', 'b2', 'c2', 'd2', 'e2'],
columns=pd.MultiIndex.from_product([['feature2'], ['keys']]),
index = [
'2022-04-15 20:20:20.100000',
'2022-04-15 20:20:20.500000',
'2022-04-15 20:20:20.900000',
'2022-04-15 20:20:21.000000',
'2022-04-15 20:20:21.100000',],)
df3 = pd.DataFrame(['a3', 'b3', 'c3', 'd3', 'e3'],
columns=pd.MultiIndex.from_product([['feature3'], ['keys']]),
index = [
'2022-04-15 20:20:19.000000',
'2022-04-15 20:20:19.200000',
'2022-04-15 20:20:20.000000',
'2022-04-15 20:20:20.200000',
'2022-04-15 20:20:23.100000',],)
then I use this merge procedure:
def merge(dfs:list[pd.DataFrame], targetColumn:'str|tuple[str]'):
from functools import reduce
if len(dfs) == 0:
return None
if len(dfs) == 1:
return dfs[0]
for df in dfs:
df.index = pd.to_datetime(df.index)
merged = reduce(
lambda left, right: pd.merge(
left,
right,
how='outer',
left_index=True,
right_index=True),
dfs)
for col in merged.columns:
if col != targetColumn:
merged[col] = merged[col].fillna(method='ffill')
return merged[merged[targetColumn].notna()]
like this:
merged = merge([df1, df2, df3], targetColumn=('target', 'key'))
which produces this:
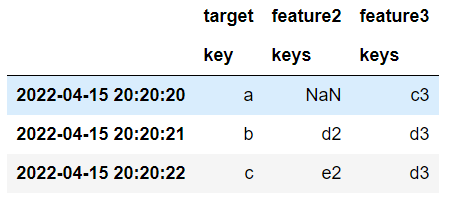
And it all works great. Problem is efficiency - notice in the merge() procedure I use reduce and an outer merge to join the dataframes together, this can make a HUGE interim dataframe which then gets filtered down. But what if my pc doesn't have enough ram to handle that huge dataframe in memory? well that's the problem I'm trying to avoid.
I'm wondering if there's a way to avoid expanding the data out into a huge dataframe while merging.
Of course a regular old merge isn't sufficient because it only merges on exactly matching indexes rather than the latest temporal index before the target variable's observation:
df1.merge(df2, how='left', left_index=True, right_index=True)
Has this kind of thing been solved efficiently? Seems like a common data science issue, since no one wants to leak future information into their models, and everyone has various inputs to merge together...
CodePudding user response:
You're in luck: pandas.merge_asof does exactly what you need!
We use the default direction='backward' argument:
A “backward” search selects the last row in the right DataFrame whose ‘on’ key is less than or equal to the left’s key.
Using your three example DataFrames:
import pandas as pd
from functools import reduce
# Convert all indexes to datetime
for df in [df1, df2, df3]:
df.index = pd.to_datetime(df.index)
# Perform as-of merges
res = reduce(lambda left, right:
pd.merge_asof(left, right, left_index=True, right_index=True),
[df1, df2, df3])
print(res)
target feature2 feature3
key keys keys
2022-04-15 20:20:20 a NaN c3
2022-04-15 20:20:21 b d2 d3
2022-04-15 20:20:22 c e2 d3
CodePudding user response:
Here's some code that works for your example. I'm not sure about more general cases of multi-indexed columns, but in any event it contains the basic ideas for merging on a single temporal index.
merged = df1.copy(deep=True)
for df in [df2, df3]:
idxNew = df.index.get_indexer(merged.index, method='pad')
idxMerged = [i for i, x in enumerate(idxNew) if x != -1]
idxNew = [x for x in idxNew if x != -1]
n = len(merged.columns)
merged[df.columns] = None
merged.iloc[idxMerged,n:] = df.iloc[idxNew,:].set_index(merged.index[idxMerged])
print(merged)
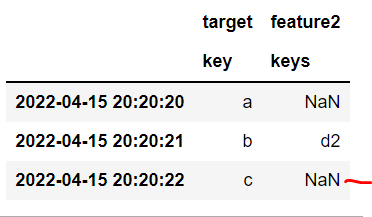
Output:
target feature2 feature3
key keys keys
2022-04-15 20:20:20.000000 a None c3
2022-04-15 20:20:21.000000 b d2 d3
2022-04-15 20:20:22.000000 c e2 d3