I have a raw dataset like below:
| ColA | ColB | duration | interval | Counter |
|---|---|---|---|---|
| A | SD | 2 | 4 | 1 |
| A | SD | 3 | 3 | 2 |
| A | UD | 2 | 1 | 10 |
| B | UD | 1 | 2 | 2 |
| B | UD | 2 | 2 | 2 |
| B | SD | 3 | 3 | 13 |
| B | SD | 1 | 4 | 19 |
I am expecting an output result like below:
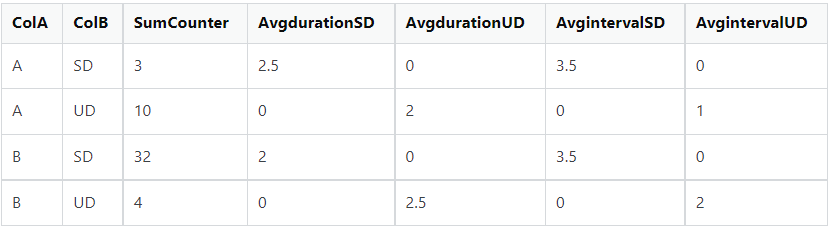
Explanation of the output:
- SumCounter is the sum of counter values on the group by ColA and ColB values.
- AvgdurationSD/UD and AvgIntervalSD/UD are created by taking the average over ColA and ColB and having a 0 value incase the columns dont match the criteria (e.g. AvgDurationSD and AvIntervalSD has 0 value for a group of ColA = A and ColB = UD.
I understand that I have to use group by and agg functions to apply here but I am not really sure how to apply conditions for ColB on individual new columns.
Any help is appreciated:)
CodePudding user response:
Use DataFrame.pivot_table with helper column new by copy like ColB, then flatten MultiIndex and add ouput to new DataFrame created by aggregate sum:
df1 = (df.assign(new=df['ColB'])
.pivot_table(index=['ColA', 'ColB'],
columns='new',
values=['interval','duration'],
fill_value=0,
aggfunc='mean'))
df1.columns = df1.columns.map(lambda x: f'{x[0]}{x[1]}')
df = (df.groupby(['ColA','ColB'])['Counter']
.sum()
.to_frame(name='SumCounter')
.join(df1).reset_index())
print (df)
ColA ColB SumCounter durationSD durationUD intervalSD intervalUD
0 A SD 3 2.5 0.0 3.5 0
1 A UD 10 0.0 2.0 0.0 1
2 B SD 32 2.0 0.0 3.5 0
3 B UD 4 0.0 1.5 0.0 2
CodePudding user response:
You can try group by column A and group by column B with Named Aggregation
out = df.groupby('ColA').apply(lambda g: g.groupby('ColB').agg({'duration': [(f'{g["ColB"].iloc[0]}', 'mean')],
'interval': [(f'{g["ColB"].iloc[0]}', 'mean')],
'Counter': 'sum'})).fillna(0)
print(out)
duration interval Counter duration interval
SD SD sum UD UD
ColA ColB
A SD 2.5 3.5 3 0.0 0.0
UD 2.0 1.0 10 0.0 0.0
B SD 0.0 0.0 32 2.0 3.5
UD 0.0 0.0 4 1.5 2.0
Then rename the multi index column
out.columns = ['SumCounter' if 'Counter' in col[0] else f'Avg{col[0]}{col[1]}' for col in out.columns.values]
print(out)
AvgdurationSD AvgintervalSD SumCounter AvgdurationUD AvgintervalUD
ColA ColB
A SD 2.5 3.5 3 0.0 0.0
UD 2.0 1.0 10 0.0 0.0
B SD 0.0 0.0 32 2.0 3.5
UD 0.0 0.0 4 1.5 2.0
CodePudding user response:
One option with groupby:
temp = (df
.assign(dummy = df.ColB)
.groupby(['ColA','ColB','dummy'])
.agg({'duration':'mean', 'interval':'mean', 'Counter':'sum'})
.rename(columns = {'Counter':'SumCounter'})
.set_index('SumCounter', append = True)
.unstack('dummy', fill_value = 0)
)
temp.columns = temp.columns.map(lambda x: f"Avg{''.join(x)}")
temp.reset_index()
ColA ColB SumCounter AvgdurationSD AvgdurationUD AvgintervalSD AvgintervalUD
0 A SD 3 2.5 0.0 3.5 0.0
1 A UD 10 0.0 2.0 0.0 1.0
2 B SD 32 2.0 0.0 3.5 0.0
3 B UD 4 0.0 1.5 0.0 2.0