I am using PostgreSQL 13 and has intermediate level experience with PostgreSQL.
I have a table named audit_log. Whenever a user logs in into the system, I store that activity in this table.
Below is my table structure, followed by datatype and index access method
Column | Data Type | Index name | Idx Access Type
------------- ----------------------------- --------------------------- ---------------------------
id | bigint | |
log_time | timestamp with time zone | idx_log_time | btree
user_id | text | idx_user_id | btree
customer_id | bigint | idx_customer_id | btree
is_active | boolean | idx_is_active | btree
is_delete | boolean | idx_is_delete | btree
I want to get unique users who are logged in into the system for a given customer in last 30 days.
There are two customers cust1 & cust2 and total records in audit_log table are 2,24,11,490
For cust1 , when I execute below query, I get 4,374 unique users who are logged in into the system in last 30 days and the execution time is 792 ms.
SELECT COUNT(DISTINCT user_id) FROM audio_log WHERE is_active=TRUE AND is_delete=FALSE AND customer_id=1 AND log_time BETWEEN '2022-01-01 00:00:00' AND '2022-01-31 00:00:00'
Please note that the total logged in users for cust1 in last 30 days is 9,747.
Problem Area
For cust2 , when I execute below query, I get 88,568 unique users who are logged in into the system in last 30 days and the execution time is 3 sec.
SELECT COUNT(DISTINCT user_id) FROM audio_log WHERE is_active=TRUE AND is_delete=FALSE AND customer_id=2 AND log_time BETWEEN '2022-01-01 00:00:00' AND '2022-01-31 00:00:00'
Please note that the total logged in users for cust2 in last 30 days is 4,86,519.
Problem
My concern is that this query should take less than 1 sec for cust2. So is there any way we can optimize and reduce the execution time?
Below is Explain the query plan
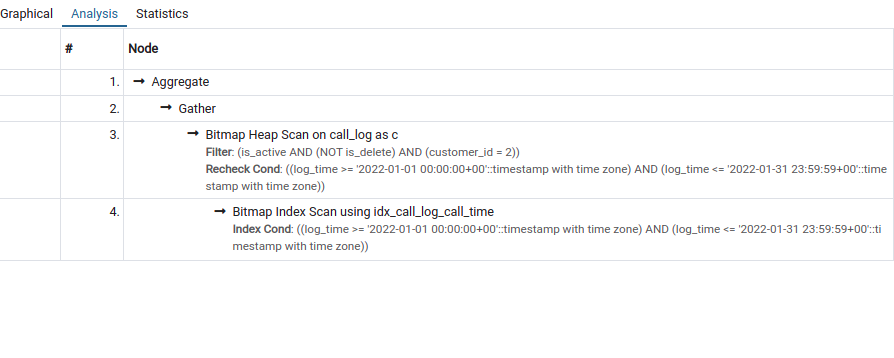 Below is my pg_settings
Below is my pg_settings
Tried Solutions
BRIN Index I applied BRIN index for
log_timecolumn but it took even more time to execute the queryGROUP BY option I used the
GROUP BYclause as suggested in few solutions but that also didn't improve the performance.
Please guide. Thanks
UPDATE
I have to add new conditon which will not consider given list of user_id in distinct count.
Below query takes 1.2 Sec for execution.
SELECT COUNT(DISTINCT user_id) FROM audio_log WHERE is_active=TRUE AND is_delete=FALSE AND customer_id=2 AND log_time BETWEEN '2022-01-01 00:00:00' AND '2022-01-31 00:00:00'
When i used not in above query , it takes more time to execute. below is my updated query.
SELECT COUNT(DISTINCT user_id) FROM audio_log WHERE is_active=TRUE AND is_delete=FALSE AND customer_id=2 AND log_time BETWEEN '2022-01-01 00:00:00' AND '2022-01-31 00:00:00' AND user_id not in ('sndka__sjkd_jask_ldkl','eydu_iehc_jksd_hcjk_hsdk')
Added Index
CREATE INDEX cust_time_user ON audio_log USING BTREE (customer_id, is_active, is_delete, log_time, user_id);
Is there any way to optimize it??
CodePudding user response:
This is a job for a multicolumn BTREE index. Your query, annotated, is this.
SELECT COUNT(DISTINCT user_id) -- item to deduplicate
FROM audio_log
WHERE is_active=TRUE -- equality filter
AND is_delete=FALSE -- equality filter
AND customer_id=1 -- most selective equality filter
AND log_time BETWEEN -- range filter
'2022-01-01 00:00:00' AND '2022-01-31 00:00:00'
In BTREE indexes, equality filters come first, then range filters, then items you want to deduplicate. So, use this index. I named it cust_time_user but you can name it anything you wish.
CREATE INDEX cust_time_user ON audio_log USING BTREE
(customer_id, is_active, is_delete, log_time, user_id);
Postgres can satisfy your query from this BTREE index, by random accessing the first eligible row, then scanning it sequentially to find the last eligible row.
You may have an error in your range filter: BETWEEN is generally unsuitable for time-range filters. For best results use >= for the beginning of the range and < for the end of the range. You want, I believe,
AND log_time >= '2022-01-01 00:00:00' -- earliest day
AND log_time < '2022-02-01 00:00:00' -- day after the latest day
Pro tip Often it doesn't make sense to add lots of single-column indexes to tables. Indexes are most useful when designed to help satisfy queries of particular shapes. Read this for more excellent information https://use-the-index-luke.com/