I have a sample data that has NAs in each of the column and only one value. I want to condense the table by removing all NAs but keeping only the value in a single row.
sample input:
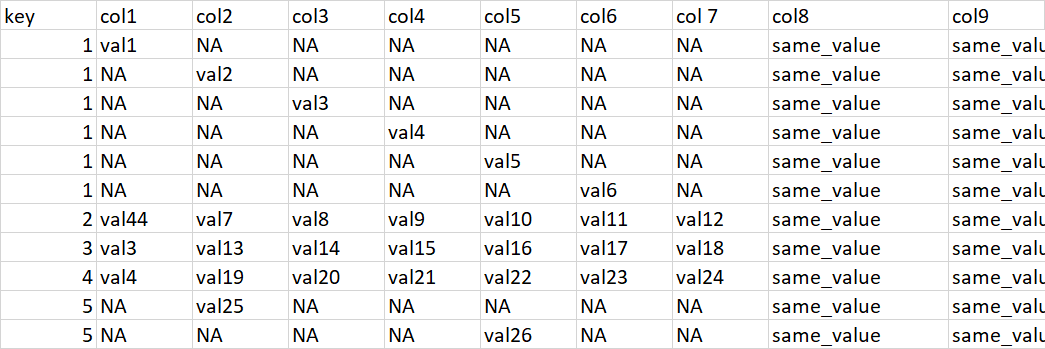 sample input code:
sample input code:
structure(list(key = c(1L, 1L, 1L, 1L, 1L, 1L, 2L, 3L, 4L, 5L,
5L), col1 = c("val1", NA, NA, NA, NA, NA, "val44", "val3", "val4",
NA, NA), col2 = c(NA, "val2", NA, NA, NA, NA, "val7", "val13",
"val19", "val25", NA), col3 = c(NA, NA, "val3", NA, NA, NA, "val8",
"val14", "val20", NA, NA), col4 = c(NA, NA, NA, "val4", NA, NA,
"val9", "val15", "val21", NA, NA), col5 = c(NA, NA, NA, NA, "val5",
NA, "val10", "val16", "val22", NA, "val26"), col6 = c(NA, NA,
NA, NA, NA, "val6", "val11", "val17", "val23", NA, NA), col.7 = c(NA,
NA, NA, NA, NA, NA, "val12", "val18", "val24", NA, NA), col8 = c("same_value",
"same_value", "same_value", "same_value", "same_value", "same_value",
"same_value", "same_value", "same_value", "same_value", "same_value"
), col9 = c("same_value", "same_value", "same_value", "same_value",
"same_value", "same_value", "same_value", "same_value", "same_value",
"same_value", "same_value")), class = "data.frame", row.names = c(NA,
-11L))
sample output :

output code:
structure(list(key = 1:5, col1 = c("val1", "val44", "val3", "val4",
NA), col2 = c("val2", "val7", "val13", "val19", "val25"), col3 = c("val3",
"val8", "val14", "val20", "val26"), col4 = c("val4", "val9",
"val15", "val21", NA), col5 = c("val5", "val10", "val16", "val22",
NA), col6 = c("val6", "val11", "val17", "val23", NA), col.7 = c(NA,
"val12", "val18", "val24", NA), col8 = c("same_value", "same_value",
"same_value", "same_value", "same_value"), col9 = c("same_value",
"same_value", "same_value", "same_value", "same_value")), class = "data.frame", row.names = c(NA,
-5L))
CodePudding user response:
A possible solution, based on tidyr::fill:
library(tidyverse)
df %>%
group_by(key) %>%
fill(2:8, .direction = "updown") %>%
distinct() %>%
ungroup
#> # A tibble: 5 x 10
#> key col1 col2 col3 col4 col5 col6 col.7 col8 col9
#> <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1 val1 val2 val3 val4 val5 val6 <NA> same_value same_value
#> 2 2 val44 val7 val8 val9 val10 val11 val12 same_value same_value
#> 3 3 val3 val13 val14 val15 val16 val17 val18 same_value same_value
#> 4 4 val4 val19 val20 val21 val22 val23 val24 same_value same_value
#> 5 5 <NA> val25 <NA> <NA> val26 <NA> <NA> same_value same_value
CodePudding user response:
You can use a single summarize call across all columns and take the maximum value among each group.
library(dplyr)
dat %>%
group_by(key) %>%
summarise(across(everything(), ~ max(.x, na.rm = T)))
#> # A tibble: 5 x 10
#> key col1 col2 col3 col4 col5 col6 col.7 col8 col9
#> <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1 val1 val2 val3 val4 val5 val6 <NA> same_value same_value
#> 2 2 val44 val7 val8 val9 val10 val11 val12 same_value same_value
#> 3 3 val3 val13 val14 val15 val16 val17 val18 same_value same_value
#> 4 4 val4 val19 val20 val21 val22 val23 val24 same_value same_value
#> 5 5 <NA> val25 <NA> <NA> val26 <NA> <NA> same_value same_value
And a slightly longer version without the warning messages:
dat %>%
group_by(key) %>%
summarise(across(everything(), ~ ifelse(all(is.na(.x)), NA, max(.x, na.rm = T))))
On the side, here's a base R option:
as.data.frame(do.call(rbind, lapply(split(dat, dat$key), function(a) sapply(a, function(x) x[!is.na(x)][1]))))