So, let's assume I have a tensor like this:
[[0,18],
[1,19],
[2, 3],
[3,19],
[4, 18]]
I need to delete rows that contains duplicates in the second column only by using tensorflow. The final output should be this:
[[0,18],
[1,19],
[2, 3]]
CodePudding user response:
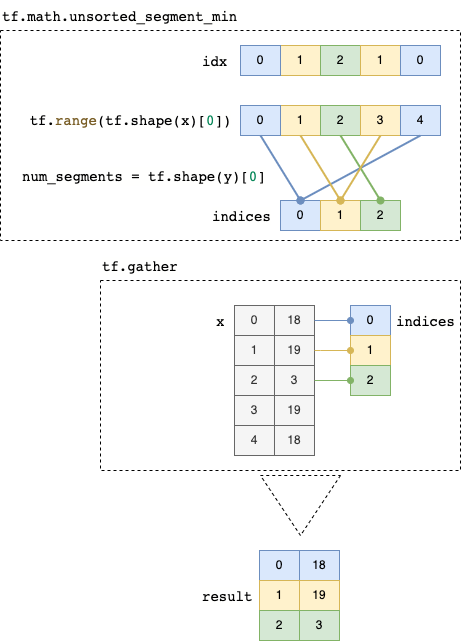
You should be able to solve this with tf.math.unsorted_segment_min and tf.gather:
import tensorflow as tf
x = tf.constant([[0,18],
[1,19],
[2, 3],
[3,19],
[4, 18]])
y, idx = tf.unique(x[:, 1])
indices = tf.math.unsorted_segment_min(tf.range(tf.shape(x)[0]), idx, tf.shape(y)[0])
result = tf.gather(x, indices)
print(result)
tf.Tensor(
[[ 0 18]
[ 1 19]
[ 2 3]], shape=(3, 2), dtype=int32)
Here is a simple explanation to what is happening after calling tf.unique: