I have defined small function that read different tables from list
from pyspark.sql.functions import *
df=spark.createDataFrame([
('America/New_York','2020-02-01 10:00:00')
,('Europe/Lisbon','2020-02-01 10:00:00')
,('Europe/Madrid','2020-02-01 10:00:00')
,('Europe/London', '2020-02-01 10:00:00')
,('America/Sao_Paulo', '2020-02-01 10:00:00')
]
,["OriginTz","Time"])
df2=spark.createDataFrame([
('Africa/Nairobi', '2020-02-01 10:00:00')
,('Asia/Damascus', '2020-02-01 10:00:00')
,('Asia/Singapore', '2020-02-01 10:00:00')
,('Atlantic/Bermuda','2020-02-01 10:00:00')
,('Canada/Mountain','2020-02-01 10:00:00')
,('Pacific/Tahiti','2020-02-01 10:00:00')
]
,["OriginTz", "Time"])
df.createOrReplaceTempView("test")
df2.createOrReplaceTempView("test2")
tables = ["test", "test2"]
frames = list(range(0,2))
def hive_read_func(tables, frames):
for table, frame in zip(tables, frames):
globals()["dttf" str(frame)] = eval(f'spark.sql("select * from {table}")')
it's perfectly working when I am calling function - hive_read_func(tables, frames)
but when I do the same in cloudera I am getting below error message, I am unable to figure it out. can some one please help me.
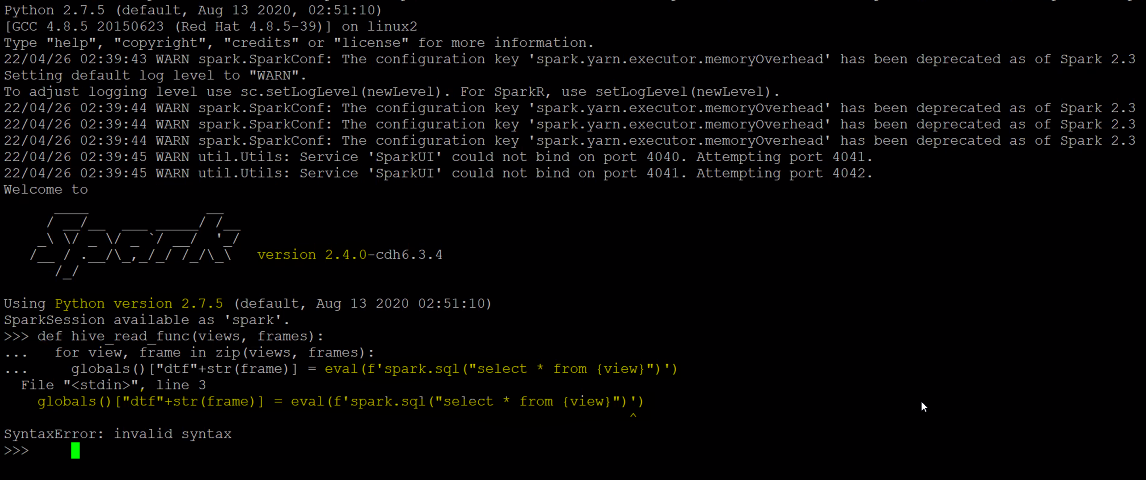
Also sharing image where I run the same function in my local system:
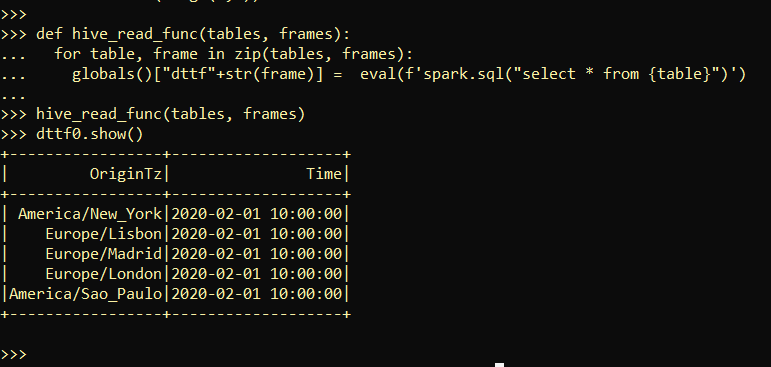
which is working perfectly fine, please look at below image:
CodePudding user response:
I got the answer: this is because of version f-string is available after python 3.6 (said by @AdibP) but I run it in python version 2.6. so got error, now I rewrite the function with out f-string:
def hive_read_func(tables, frames):
for table, frame in zip(tables, frames):
inner_code = "select * from" " " str(table)
globals()["dttf" str(frame)] = spark.sql(inner_code)