When I try to do the math expression from the following code the matrix values are not consistent, how can I fix that?
#pragma omp parallel num_threads (NUM_THREADS)
{
#pragma omp for
for(int i = 1; i < qtdPassos; i )
{
#pragma omp critical
matriz[i][0] = matriz[i-1][0]; /
for (int j = 1; j < qtdElementos-1; j )
{
matriz[i][j] = (matriz[i-1][j-1] (2 * matriz[i-1][j]) matriz[i-1][j 1]) / 4; // Xi(t 1) = [Xi-1 ^ (t) 2 * Xi ^ (t) Xi 1 ^ (t)] / 4
}
matriz[i][qtdElementos-1] = matriz[i-1][qtdElementos-1];
}
}
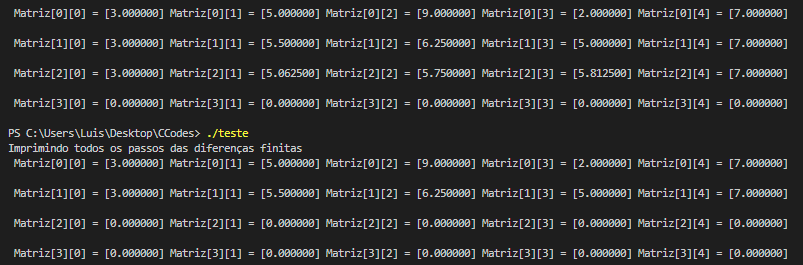
CodePudding user response:
The problem comes from a race condition which is due to a loop carried dependency. The encompassing loop cannot be parallelised (nor the inner loop) since loop iterations matriz read/write the current and previous row. The same applies for the column.
Note that OpenMP does not check if the loop can be parallelized (in fact, it theoretically cannot in general). It is your responsibility to check that. Additionally, note that using a critical section for the whole iteration serializes the execution defeating the purpose of a parallel loop (in fact, it will be slower due to the overhead of the critical section). Note also that #pragma omp critical only applies on the next statement. Protecting the line matriz[i][0] = matriz[i-1][0]; is not enough to avoid the race condition.
I do not think this current code can be (efficiently) parallelised. That being said, if your goal is to implement a 1D/2D stencil, then you can use a double buffering technique (ie. write in a 2D array that is different from the input array). A similar logic can be applied for 1D stencil repeated multiple times (which is apparently what you want to do). Note that the results will be different in that case. For the 1D stencil case, this double buffering strategy can fix the dependency issue and enable you to parallelize the inner-loop. For the 2D stencil case, the two nested loops can be parallelized.