My dataframe:
structure(list(Observation = c("Apple", "Blueberry", "Cirtus",
"Dates", "Eggplant"), Topic = 1:5, Gamma = c(0.1, 0.1, 0.2, 0.2,
0.1)), class = "data.frame", row.names = c(NA, -5L))
Observation Topic Gamma
1 Apple 1 0.1
2 Blueberry 2 0.1
3 Cirtus 3 0.2
4 Dates 4 0.2
5 Eggplant 5 0.1
How can I tell R to add the values of 1, 3, and 5, and 2 and 4, and then save it in a new column? For example:
| Observation | Topic | Gamma | new variable |
|---|---|---|---|
| Apple | 1 | .10 | .40 |
| Blueberry | 2 | .10 | .30 |
| Cirtus | 3 | .20 | .40 |
| Dates | 4 | .20 | .30 |
| Eggplant | 5 | .10 | .40 |
Essentially, I'd like each observation to have a new value that sums up the gamma scores of topics 1, 3, and 5, as well as topics 2 and 4.
Update: Clarification: I am not trying to add even topic numbers or odd topic numbers. Sometimes it will be a mixture of both. See this new table as an example:
| Observation | Topic | Gamma | new variable |
|---|---|---|---|
| Apple | 1 | .10 | .10 |
| Blueberry | 2 | .10 | .70 |
| Cirtus | 3 | .20 | .40 |
| Dates | 4 | .20 | .40 |
| Eggplant | 5 | .10 | .70 |
| Fruits | 6 | .50 | .70 |
In this example, I left topic 1 alone, added topics 2, 5, and 6, and added topics 3 and 4.
Update: Clarification:
| Observation | Topic | Gamma | new variable |
|---|---|---|---|
| Apple | 1 | .10 | .10 |
| Apple | 2 | .10 | .70 |
| Apple | 3 | .20 | .40 |
| Apple | 4 | .20 | .40 |
| Apple | 5 | .10 | .70 |
| Apple | 6 | .50 | .70 |
| Blueberry | 1 | .20 | .20 |
| Blueberry | 2 | .10 | .60 |
| Blueberry | 3 | .30 | .80 |
| Blueberry | 4 | .50 | .80 |
| Blueberry | 5 | .40 | .60 |
| Blueberry | 6 | .10 | .60 |
In this example, Each fruit (observation) has their own set of values for each topic and I summed the same topics as listed above (2, 5, and 6, 3 and 4) per fruit.
CodePudding user response:
Update II on new request:
library(dplyr)
df %>%
group_by(Observation, grp = case_when(Topic %in% 1 ~ 1,
Topic %in% c(2,5,6) ~ 2,
Topic %in% c(3,4) ~ 3)) %>%
mutate(new_variable = sum(Gamma)) %>%
ungroup %>%
select(-grp)
Observation Topic Gamma new_variable
<chr> <int> <dbl> <dbl>
1 Apple 1 0.1 0.1
2 Apple 2 0.1 0.7
3 Apple 3 0.2 0.4
4 Apple 4 0.2 0.4
5 Apple 5 0.1 0.7
6 Apple 6 0.5 0.7
7 Blueberry 1 0.2 0.2
8 Blueberry 2 0.1 0.6
9 Blueberry 3 0.3 0.8
10 Blueberry 4 0.5 0.8
11 Blueberry 5 0.4 0.6
12 Blueberry 6 0.1 0.6
Update: on new request of OP. This solution is inspired fully by PaulS solution (credits to him):
library(dplyr)
df %>%
group_by(grp = case_when(Topic %in% 1 ~ 1,
Topic %in% c(2,5,6) ~ 2,
Topic %in% c(3,4) ~ 3)) %>%
mutate(new_variable = sum(Gamma)) %>%
ungroup %>%
select(-grp)
Observation Topic Gamma new_variable
<chr> <int> <dbl> <dbl>
1 Apple 1 0.1 0.1
2 Blueberry 2 0.1 0.7
3 Cirtus 3 0.2 0.4
4 Dates 4 0.2 0.4
5 Eggplant 5 0.1 0.7
6 Fruits 6 0.5 0.7
First answer:
We could sum Gamma after identifying odd and even rows in an ifelse statement:
In this case row_number could be replaced by Topic
library(dplyr)
df %>%
mutate(new_variable = ifelse(row_number() %% 2 == 1,
sum(Gamma[row_number() %% 2 == 1]), # odd 1,3,5
sum(Gamma[row_number() %% 2 == 0])) # even 2,4
)
Observation Topic Gamma new_variable
1 Apple 1 0.1 0.4
2 Blueberry 2 0.1 0.3
3 Cirtus 3 0.2 0.4
4 Dates 4 0.2 0.3
5 Eggplant 5 0.1 0.4
data:
structure(list(Observation = c("Apple", "Blueberry", "Cirtus",
"Dates", "Eggplant"), Topic = 1:5, Gamma = c(0.1, 0.1, 0.2, 0.2,
0.1)), class = "data.frame", row.names = c(NA, -5L))
Microbenchmark: AndrewGB's base R is fastest
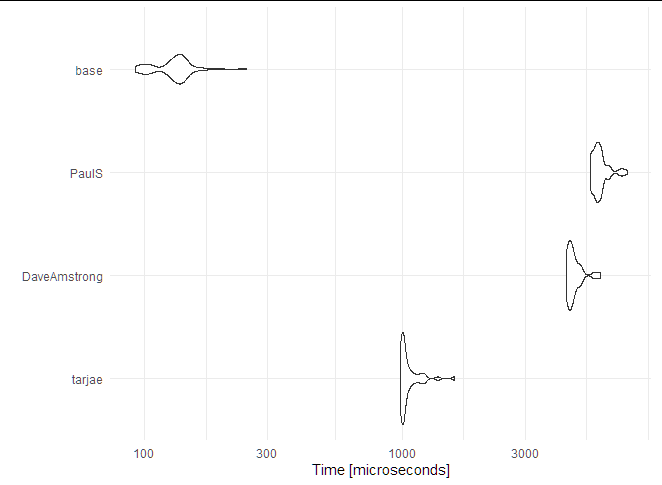
CodePudding user response:
This should do it.
dat <- structure(list(Observation = c("Apple", "Blueberry", "Cirtus",
"Dates", "Eggplant"),
Topic = 1:5, Gamma = c(0.1, 0.1, 0.2, 0.2, 0.1)),
row.names = c(NA, 5L), class = "data.frame")
library(tidyverse)
dat %>%
mutate(even = as.numeric(Topic %% 2 == 0)) %>%
group_by(even) %>%
mutate(new_variable = sum(Gamma))
#> # A tibble: 5 × 5
#> # Groups: even [2]
#> Observation Topic Gamma even new_variable
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 Apple 1 0.1 0 0.4
#> 2 Blueberry 2 0.1 1 0.3
#> 3 Cirtus 3 0.2 0 0.4
#> 4 Dates 4 0.2 1 0.3
#> 5 Eggplant 5 0.1 0 0.4
Created on 2022-05-13 by the reprex package (v2.0.1)
CodePudding user response:
Another possible solution:
library(dplyr)
df %>%
group_by(grp = if_else(Topic %in% c(1, 3, 5), 1, 2)) %>%
mutate(new_variable = sum(Gamma)) %>%
ungroup %>%
select(-grp)
#> # A tibble: 5 × 4
#> Observation Topic Gamma new_variable
#> <chr> <int> <dbl> <dbl>
#> 1 Apple 1 0.1 0.4
#> 2 Blueberry 2 0.1 0.3
#> 3 Cirtus 3 0.2 0.4
#> 4 Dates 4 0.2 0.3
#> 5 Eggplant 5 0.1 0.4
CodePudding user response:
Update II (but will work with the first update as well)
With base R, we can first create a new grouping column, where we copy the Topic column as factor, then we can change the levels according to what rows you want to group together to sum. Then, we can get the sum of the Gamma column by the Topic and row groups. Then, remove the grp column.
df$grp <- factor(df$Topic)
levels(df$grp) <- list(
"1" = 1,
"2" = c(2,5,6),
"3" = c(3,4)
)
df$new_variable <- ave(df$Gamma, df[,c(1,4)], FUN = sum)
df <- df[,-4]
Output
Observation Topic Gamma new_variable
1 Apple 1 0.1 0.1
2 Apple 2 0.1 0.7
3 Apple 3 0.2 0.4
4 Apple 4 0.2 0.4
5 Apple 5 0.1 0.7
6 Apple 6 0.5 0.7
7 Blueberry 1 0.2 0.2
8 Blueberry 2 0.1 0.6
9 Blueberry 3 0.3 0.8
10 Blueberry 4 0.5 0.8
11 Blueberry 5 0.4 0.6
12 Blueberry 6 0.1 0.6
Data
df <- structure(list(Observation = c("Apple", "Apple", "Apple", "Apple",
"Apple", "Apple", "Blueberry", "Blueberry", "Blueberry", "Blueberry",
"Blueberry", "Blueberry"), Topic = c(1L, 2L, 3L, 4L, 5L, 6L,
1L, 2L, 3L, 4L, 5L, 6L), Gamma = c(0.1, 0.1, 0.2, 0.2, 0.1, 0.5,
0.2, 0.1, 0.3, 0.5, 0.4, 0.1)), class = "data.frame", row.names = c(NA,
-12L))
First Answer
With base R, we can use ave to get the sum for each group. Here, I create the group using a logical since we only have 2 groups.
df$new_variable <- ave(df$Gamma, row.names(df) %in% c(1, 3, 5), FUN=sum)
Output
Observation Topic Gamma new_variable
1 Apple 1 0.1 0.4
2 Blueberry 2 0.1 0.3
3 Cirtus 3 0.2 0.4
4 Dates 4 0.2 0.3
5 Eggplant 5 0.1 0.4
Or we could get the sum for each grouping of rows and assign to a new column by index.
df$new_variable[c(1, 3, 5)] <- sum(df$Gamma[c(1, 3, 5)], na.rm = T)
df$new_variable[c(2, 4)] <- sum(df$Gamma[c(2, 4)], na.rm = T)