Given this code:
from bs4 import BeautifulSoup
from lxml import etree
import requests
import pandas as pd
URL = "https://boards.4chan.org/x/archive"
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',\
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content, "html.parser")
dom = etree.HTML(str(soup))
threads = dom.xpath('//tbody/tr')[0:2]
print(len(threads))
threads_count = 0
rows = []
for i in threads:
thread_ids = i.xpath('.//td[1]')
for j in thread_ids:
thread_id = j.text
threads_count = 1
print(f"Currently checking ID = {threads_count}/{(len(threads))}", end="")
url2 = (f'https://boards.4chan.org/x/thread/{thread_id}')
webpage = requests.get(url2)
soup = BeautifulSoup(webpage.content, "html.parser")
dom = etree.HTML(str(soup))
threads_containers = dom.xpath('//div[contains(@class,"Container")]')
for x in threads_containers:
post_id = x.xpath('.//span[@]/a[@title="Reply to this post"]')[0].text
content = x.xpath('.//blockquote[@]/descendant::text()')
new_content = []
for el in content:
if thread_id in el:
el = el " (OP)"
new_content.append(el "\n")
else:
new_content.append(el "\n")
rows.append([thread_id, post_id, ''.join(new_content)])
print("\r", end="")
df = pd.DataFrame(rows, columns=['Threads IDs', 'Posts IDs', 'Content'])
df
I get a the following DF (yours can be different because it scraps "live" archives):
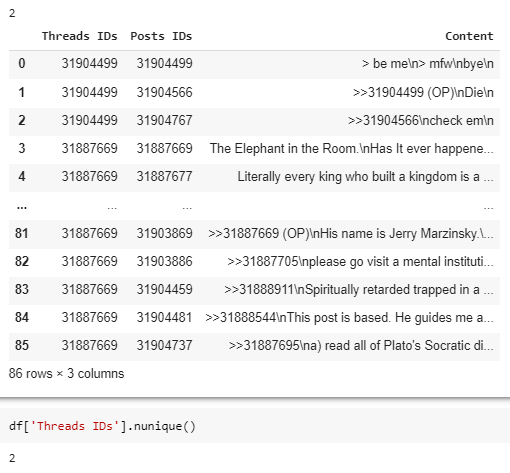
Then I use this code:
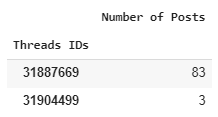
df1 = df[['Threads IDs', 'Posts IDs']].groupby('Threads IDs').count().rename(columns={'Posts IDs': 'Number of Posts'})
df1
to get the following result:
Now, what I would like, its creating a third column named "What", applying the code below but for the entire dataframe:
df.loc[df['Threads IDs'] == '31904499', 'Content'].iloc[0]
I tried to play with "apply" and the code above, without success.
If I resume: After using "groupby" to get the new DF with the "Number of Posts" by "Threads IDs", I would like to create a third column, named "What", which contains for each row the first value of "Content" ([0]) corresponding to the respective "Thread ID".
Thank you :)
CodePudding user response:
Try this
# df1.index is unique Thread IDs, so map it
df['What'] = df['Thread IDs'].map(df1['Number of Posts'])
CodePudding user response:
This will group the dataframe by 'Threads IDs' and show the first row for each group
df.groupby('Threads IDs').first()
# Out:
# Posts IDs Content
Threads IDs
# 31886119 31886119 Are Greys simply humans from the future? \nIf ...
# 31901943 31901943 In the video game Event 0, one of the main thi...
To get a dataframe with counts and the content of the first post for each thread:
df
# Threads IDs Posts IDs # Content
# 0 31886119 31886119 Are Greys simply humans from the future? \nIf ...
# 1 31886119 31886125 >>31886119 (OP)\nYou don't even know if 'Greys...
# 2 31886119 31886142 Probes for higher concious beings. They attach... ...
# .. ... ...
# 173 31901943 31904460 >>31902625\n>The moment the replikas started t...
# 174 31901943 31904484 >>31902874\nDo it, Oblivion is always the game...
df.groupby('Threads IDs').agg(['count', 'first'])['Content'] \
.rename(columns={'count':'Number Of Posts'}) \
.reset_index()
# Out:
# Threads IDs Number Of Posts first
# 0 31886119 147 Are Greys simply humans from the future? \nIf ...
# 1 31901943 31 In the video game Event 0, one of the main thi...