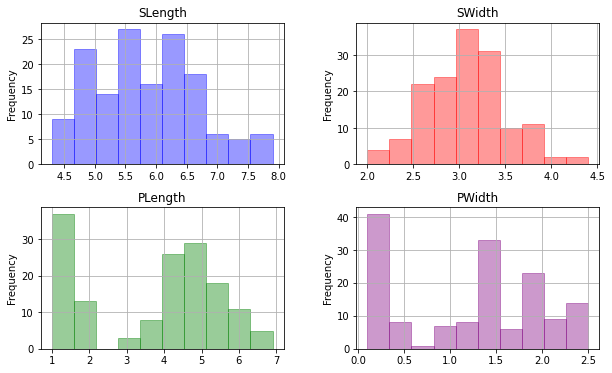
Whenever I'm making subplots, I'm used to making each plot individually and combining them all in a list.
Pandas is really cool because, with just one simple line of code, I can make a figure that contains histograms of all the features of a dataset:
hist_plot = iris.hist(alpha=0.4, figsize=(10,6))
However, I'm stumped on how to make changes to this figure. For example:
- Making each plot a different color:
color = ['blue', 'red', 'green', 'purple'] - Giving each plot a different title:
title = ['SLength', 'SWidth', 'PLength', 'PWidth'] - Adding "Frequency" label to each y axis
Is there a way to do this without having to make each plot individually? I tried this as an example, but it didn't work:
hist_plot = iris.hist(color = ['blue', 'red', 'green', 'purple'], alpha=0.4, figsize=(10,6))
CodePudding user response:
df.hist() returns a two-dimensional array of axes objects, which correspond to the subplots in their grid arrangement. To iterate over them, their flat attribute is convenient, as it contains the same objects in a flat array. You can use zip() to iterate over the subplots and your color and title lists in parallel:
from sklearn.datasets import load_iris
iris = load_iris(as_frame=True)['data']
colors = ['blue', 'red', 'green', 'purple']
titles = ['SLength', 'SWidth', 'PLength', 'PWidth']
axs = iris.hist(alpha=0.4, figsize=(10, 6))
for ax, color, title in zip(axs.flat, colors, titles):
for patch in ax.patches:
patch.set_color(color)
ax.set_title(title)
ax.set_ylabel('Frequency')