Here is some fictional data:
tibble(fruit = rep(c("apple", "pear", "orange"), each = 3),
size = rep(c("big", "medium", "small"), times = 3),
# summer stock
shopA_summer_wk1 = abs(round(rnorm(9, 10, 5), 0)),
shopA_summer_wk2 = abs(round(rnorm(9, 10, 5), 0)),
shopB_summer_wk1 = abs(round(rnorm(9, 10, 5), 0)),
shopB_summer_wk2 = abs(round(rnorm(9, 10, 5), 0)),
shopC_summer_wk1 = abs(round(rnorm(9, 10, 5), 0)),
shopC_summer_wk2 = abs(round(rnorm(9, 10, 5), 0)),
# winter stock
shopA_winter_wk1 = abs(round(rnorm(9, 8, 4), 0)),
shopA_winter_wk2 = abs(round(rnorm(9, 8, 4), 0)),
shopA_winter_wk3 = abs(round(rnorm(9, 8, 4), 0)),
shopB_winter_wk1 = abs(round(rnorm(9, 8, 4), 0)),
shopB_winter_wk2 = abs(round(rnorm(9, 8, 4), 0)),
shopB_winter_wk3 = abs(round(rnorm(9, 8, 4), 0)),
shopC_winter_wk1 = abs(round(rnorm(9, 8, 4), 0)),
shopC_winter_wk2 = abs(round(rnorm(9, 8, 4), 0)),
shopC_winter_wk3 = abs(round(rnorm(9, 8, 4), 0)))
Some data is collected for 3 shops (A, B, C) across 2 weeks in the summer and 3 weeks in the winter. The data collected is the number of fruits (apple, pear, orange) per size (big, medium, small) the shop had in stock on that particular week.
Here are the first 6 rows of of the dataset:
# fruit size shopA_summer_wk1 shopA_summer_wk2 shopB_summer_wk1 shopB_summer_wk2 shopC_summer_wk1 shopC_summer_wk2 shopA_winter_wk1 shopA_winter_wk2 shopA_winter_wk3
# <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
# 1 apple big 9 12 12 16 15 5 14 4 0
# 2 apple medium 21 16 16 1 12 11 8 8 9
# 3 apple small 10 6 18 18 22 12 4 2 0
# 4 pear big 13 7 4 12 13 6 10 6 2
# 5 pear medium 13 12 8 0 8 5 11 7 3
# 6 pear small 16 18 4 3 13 8 7 5 0
I would like to use the pivot_longer() function in R to restructure this dataset. Given that there are quite a few group categories I'm having difficulty in writing the code for this.
I would like it to look something like the following:
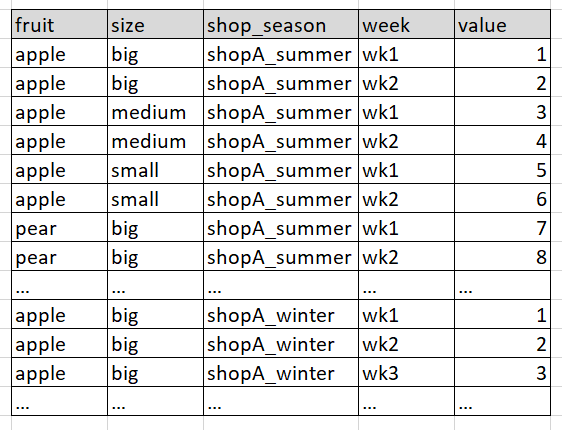
I would greatly appreciate any input :)
CodePudding user response:
Using the names_pattern argument, we can do:
pivot_longer(df, c(-fruit, -size), names_pattern = '(^.*)_wk(.*$)',
names_to = c('Shop_season', 'week'))
#> # A tibble: 135 x 5
#> fruit size Shop_season week value
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 apple big shopA_summer 1 11
#> 2 apple big shopA_summer 2 8
#> 3 apple big shopB_summer 1 4
#> 4 apple big shopB_summer 2 24
#> 5 apple big shopC_summer 1 9
#> 6 apple big shopC_summer 2 10
#> 7 apple big shopA_winter 1 9
#> 8 apple big shopA_winter 2 12
#> 9 apple big shopA_winter 3 5
#> 10 apple big shopB_winter 1 5
#> # ... with 125 more rows
You might also want to separate shop and season, since these are really two different variables:
pivot_longer(df, c(-fruit, -size), names_pattern = '(^.*)_wk(.*$)',
names_to = c('Shop_season', 'week')) %>%
separate(Shop_season, into = c('shop', 'season'))
#> # A tibble: 135 x 6
#> fruit size shop season week value
#> <chr> <chr> <chr> <chr> <chr> <dbl>
#> 1 apple big shopA summer 1 11
#> 2 apple big shopA summer 2 8
#> 3 apple big shopB summer 1 4
#> 4 apple big shopB summer 2 24
#> 5 apple big shopC summer 1 9
#> 6 apple big shopC summer 2 10
#> 7 apple big shopA winter 1 9
#> 8 apple big shopA winter 2 12
#> 9 apple big shopA winter 3 5
#> 10 apple big shopB winter 1 5
#> #... with 125 more rows
CodePudding user response:
If data is dt, then
pivot_longer(
data = dt,
cols = -c(fruit:size),
names_to = c("shop_season", "week"),
names_pattern = "(.*)_(.*)"
)
Output:
# A tibble: 135 x 5
fruit size shop_season week value
<chr> <chr> <chr> <chr> <dbl>
1 apple big shopA_summer wk1 13
2 apple big shopA_summer wk2 12
3 apple big shopB_summer wk1 9
4 apple big shopB_summer wk2 9
5 apple big shopC_summer wk1 7
6 apple big shopC_summer wk2 17
7 apple big shopA_winter wk1 10
8 apple big shopA_winter wk2 17
9 apple big shopA_winter wk3 12
10 apple big shopB_winter wk1 8