I'm new to OpenCL and I'm working on converting an existing algorithm to OpenCL. In this process, I am experiencing a phenomenon that I cannot solve on my own, and I would like to ask some help.
Here's details.
My kernel is applied to images of different size (to be precise, each layer of the Laplacian pyramid).
I get normal results for images of larger size such as 3072 x 3072, 1536 x 1536. But I get abnormal results for smaller images such as 12 x 12, 6 x 6, 3 x 3, 2 x 2.
At first, I suspected that clEnqueueNDRangeKernel had a bottom limit for dimensions, causing this problem. So, I added printf to the beginning of the kernel as follows. It is confirmed that all necessary kernel instances are executed.
__kernel void GetValueOfB(/* parameters */)
{
uint xB = get_global_id(0);
uint yB = get_global_id(1);
printf("(%d, %d)\n", xB, yB);
// calculation code is omitted
}
So after wandering for a while, I added the same printf to the end of the kernel. When I did this, it was confirmed that printf works only for some pixel positions. For pixel positions not output by printf, the calculated values in the resulting image are incorrect, and as a result, I concluded that some kernel instances terminate abnormally before completing the calculations.
__kernel void GetValueOfB(/* parameters */)
{
uint xB = get_global_id(0);
uint yB = get_global_id(1);
printf("(%d, %d)\n", xB, yB);
// calculation code is omitted
printf("(%d, %d, %f)\n", xB, yB, result_for_this_position);
}
It seems that there is no problem with the calculation of the kernel. If I compile the kernel turning off the optimization with the -cl-opt-disable option, I get perfectly correct results for all images regardless of their size. In addition to that, with NVIDA P4000, it works correct. Of course, in theses cases, I confirmed that the printf added at the bottom of the Kernel works for all pixels.
Below I put additional information and attach a part of the code I wrote.
Any advice is welcomed and appreciated. Thank you.
SDK: Intel® SDK For OpenCL™ Applications 2020.3.494
Platform: Intel(R) OpenCL HD Graphics
for all images
{
...
const size_t globalSize[2] = { size_t(vtMatB_GPU_LLP[nLayerIndex].cols), size_t(vtMatB_GPU_LLP[nLayerIndex].rows) };
err = clEnqueueNDRangeKernel(_pOpenCLManager->GetCommandQueue(), kernel, 2,
NULL, globalSize, NULL, 0, NULL, NULL);
if (CL_SUCCESS != err)
return -1;
// I tried with this but it didn't make any difference
//std::this_thread::sleep_for(std::chrono::seconds(1));
err = clFinish(_pOpenCLManager->GetCommandQueue());
if (CL_SUCCESS != err)
return -1;
err = clEnqueueReadBuffer(_pOpenCLManager->GetCommandQueue(), memMatB, CL_TRUE,
0, sizeof(float) * vtMatB_GPU_LLP[nLayerIndex].cols *
vtMatB_GPU_LLP[nLayerIndex].rows, vtMatB_GPU_LLP[nLayerIndex].data, 0, nullptr, nullptr);
if (CL_SUCCESS != err)
return -1;
...
}
And I tried with event, too, but it works the same way.
for all images
{
...
const size_t globalSize[2] = { size_t(vtMatB_GPU_LLP[nLayerIndex].cols), size_t(vtMatB_GPU_LLP[nLayerIndex].rows) };
cl_event event;
err = clEnqueueNDRangeKernel(_pOpenCLManager->GetCommandQueue(), kernel, 2, NULL, globalSize, NULL, 0, NULL, &event);
if (CL_SUCCESS != err)
return -1;
err = clWaitForEvents(1, &event);
if (CL_SUCCESS != err)
return -1;
err = clFinish(_pOpenCLManager->GetCommandQueue());
if (CL_SUCCESS != err)
return -1;
err = clEnqueueReadBuffer(_pOpenCLManager->GetCommandQueue(), memMatB, CL_TRUE,
0, sizeof(float) * vtMatB_GPU_LLP[nLayerIndex].cols *
vtMatB_GPU_LLP[nLayerIndex].rows, vtMatB_GPU_LLP[nLayerIndex].data, 0, nullptr, nullptr);
if (CL_SUCCESS != err)
return -1;
...
}
/////// Added contents ////////////////////////////////////////////
Would you guys please take look at this issue in the aspect of clFinsh, or clWaitEvent. Am I missing something in this regard?
Sometimes I get less correct values and sometimes I get more correct values.
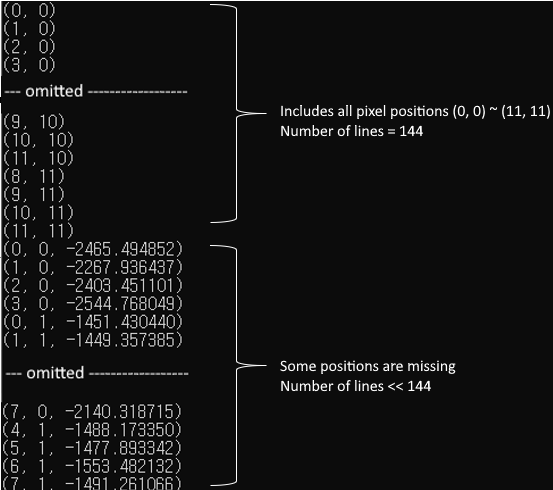
To be more specific, let's say I'm applying the kernel to 12 x 12 size image. So there're 144 pixel values.
Sometime I get correct values for 56 pixels. Sometime I get correct values for 89 pixels. Some other time I get correct value for n(less then 144) pixels.
If I turn off the OpenCL optimization when compiling the kernel by specifying -cl-opt-disable option, I get correct values for all 144 pixels.
The other thing that makes me think the calculation code is correct is that the same OpenCL code with no modification(other then device select code) runs perfectly correctly with NVIDIA P4000.
At first, I was really suspicious about the calculation code, but more I inspect code, more I'm confident there's nothing wrong with calculation code.
I know there's still a chance that there is an error in the calculation code so that there happen some exceptions anywhere during calculations.
I have plain C code for same task. I'm comparing results from those two.
CodePudding user response:
OpenCL kernels run threads in parallel on a specified global range, which in your case is the image size, with one thread per pixel.
The threads are grouped in workgroups, Workgroup size should be a multiple of 32; ideally 64 to make full use of the hardware, or 8x8 pixels in 2D. These workgroups cannot be split, so the global range must be a multiple of workgroup size.
What happens if global range is not clearly divisible by workgroup size, or smaller than workgroup size, like 3x3 pixels? Then the last workgroup is still executed with all 8x8 threads. The first 3x3 work on valid data in memory, but all the other threads read/write unallocated memory. This can cause undefined behavior or even crashes.
If you cannot have global size as a multiple of workgroup size, there is still a solution: a guard clause in the very beginning of the kernel:
if(xB>=xImage||yB>=yImage) return;
This ensures that no threads access unallocated memory.
CodePudding user response:
As you don't supply a complete reproducible code sample, here's a loose collection of comments/suggestions/advice:
1. printf in kernel code
Don't rely on large amounts of printf output from kernels. It's necessarily buffered, and some implementations don't guarantee delivery of messages - often there's a fixed size buffer and when that's full, messages are dropped.
Note that your post-calculation printf increases the total amount of output, for example.
The reliable way to check or print kernel output is to write it to a global buffer and print it in host code. For example, if you want to verify each work-item reaches a specific point in the code, consider creating a zero-initialised global buffer where you can set a flag in each work-item.
2. Events
As you asked about events, flushing, etc. Your clFinish call certainly should suffice to ensure everything has executed - if anything, it's overkill, but especially while you're debugging other issues it's a good way to rule out queuing issue.
The clWaitForEvents() call preceeding it is not a great idea, as you haven't called clFlush() after queueing the kernel whose event you're waiting for. It's fairly minor, but could be a problem on some implementations.
3. Small image sizes
You've not actually posted any of the code that deals with the images themselves, so I can only guess at potential issues there. It looks like you're not using workgroups, so you shouldn't be running into the usual multiple-of-group-size pitfall.
However, are you sure you're loading the source data correctly, and you're correctly indexing into it? There could be all sorts of pitfalls here, from alignment of pixel rows in the source data, enqueueing the kernel before filling the source buffers has completed, creating source buffers with the wrong flags, etc.
So in summary, I'd suggest:
- Don't believe in-kernel-printf if something strange is going on. Switch to something more reliable for observing the behaviour of your kernel code.
- At minimum, post all your OpenCL API calling host code. Buffer creation, setting arguments, etc. Any fragments of kernel code accessing the buffers are probably not a bad idea either.