I have a DataFrame that is looking like this (using .to_markdown() which is showing the 3 index columns as one) :
| id | col1 | col2 | |
|---|---|---|---|
| (2022, 'may', 27) | LB46 | 10 | 12 |
| (2022, 'may', 28) | LB46 | 10 | 12 |
| (2022, 'may', 29) | LB46 | 10 | 12 |
| (2022, 'may', 30) | LB46 | 10 | 12 |
| (2022, 'may', 31) | LB46 | 40 | 12 |
| (2022, 'june', 1) | LB46 | 50 | 12 |
| (2022, 'june', 2) | LB46 | 90 | 12 |
| (2022, 'june', 3) | LB46 | 110 | 12 |
An other preview using .head() :
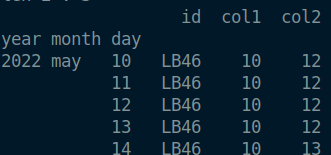
This is a multi-index Dataframe with 3 index which here are "year", "month" and "day". These index are arbitrary choose for the example, it could be any kind of index. Then I can't rely on date conversion, I want to rely on original order which is the one shown.
But I also want to do a slice between the line (2022, 'may', 29) and (2022, 'june', 1).
To do that I try to use DataFrame.loc :
df= df.loc[('2022','may','29'): ('2022', 'june', '1')]
But it leads to this error :
pandas.errors.UnsortedIndexError: 'Key length (3) was greater than MultiIndex lexsort depth (1)'
So then I tried to get my DataFrame sorted using :
df_csv.sort_index(Inplace=True)
The problem with that is that whatever options of sort_index I use, the order of my DataFrame kept altered (as for example there are no possibility to choose an order other than ascending or descending). Again I don't know the comparison function to use for the sort, so what I really want it to have it "sorted" but without any alteration of the original order.
Is there a way to achieve this ? My goal is to obtain these row as a result after the .loc :
| id | col1 | col2 | |
|---|---|---|---|
| (2022, 'may', 29) | LB46 | 10 | 12 |
| (2022, 'may', 30) | LB46 | 10 | 12 |
| (2022, 'may', 31) | LB46 | 40 | 12 |
| (2022, 'june', 1) | LB46 | 50 | 12 |
An alternative solution I would try is to get the (first) index of the row (2022, 'may', 29), the (last) index of the row (2022, 'june', 1) and then to do an iloc.
CodePudding user response:
You can try set the index level 1 as ordered category type
from pandas.api.types import CategoricalDtype
t = CategoricalDtype(categories=['may', 'june'], ordered=True)
df.index = df.index.set_levels(df.index.levels[1].astype(t), level=1)
df = df.sort_index()
out = df.loc[(2022,'may',29) : (2022, 'june', 1)]
print(out)
id col1 col2
2022 may 29 LB46 10 12
30 LB46 10 12
31 LB46 40 12
june 1 LB46 50 12
CodePudding user response:
I solve my problem as follow :
First convert the indexes type (it was not explicitly described but my example include several index types and as it's not know by advance it could be an issue) :
if df is not None:
if df.index.nlevels > 1:
df.index = pd.MultiIndex.from_frame(
pd.DataFrame(index=df.index).reset_index().astype(str)
)
else:
df.index = df.index.astype(str)
Then it's possible to do an iloc as followed to get the expected result:
df = df.iloc[
df.index.get_loc(('2022','may','29':) : df.index.get_loc('2022','june','01')
]