I am trying to generate a set of summary statistics for each day in a dataset. Specifically, I want to know the percentage of time spent within, above, and below a certain range of values.
Starting example df:
date value
2022-05-01 17:03:45 120
2022-05-02 17:08:45 55
2022-05-03 17:13:45 230
2022-05-04 17:18:45 285
2022-05-05 17:23:45 140
I then make a new column with the following conditions:
df['range'] = ['extreme low' if bgl <= 54 else 'low' if bgl < 70 else 'extreme high' if bgl > 250 else 'high' if bgl >= 180 else 'in range' for bgl in df['bgl']]
df.head()
date value range
2022-05-01 17:03:45 120 in range
2022-05-02 17:08:45 55 low
2022-05-03 17:13:45 230 high
2022-05-04 17:18:45 285 extreme high
2022-05-05 17:23:45 41 extreme low
The issue:
There are some days where, for example, there are no values in the extreme low category. Even if this is true, I would still like to see extreme low: 0 in my summary statistics.
When I group by date and use value_counts() and reindex(), my results are very close to what I want. However, even with fill_value=0, I don't get a row with "0":
categories = ['extreme low', 'low', 'in range', 'high', 'extreme high']
daily_summaries = df.groupby(pd.Grouper(key='date', axis=0, freq='D'))['range'].value_counts(normalize=True).reindex(categories, level=1, fill_value=0).mul(100).round(1)
print(daily_summaries)
Resulting in:
date range
2022-05-02 low 2.7
in range 77.8
high 13.6
extreme high 5.9
My desired output is this:
date range
2022-05-02 extreme low 0
low 2.7
in range 77.8
high 13.6
extreme high 5.9
I hope that makes sense. Any help or advice would be greatly appreciated. I'm sure I'm missing something rather simple, but I can't seem to figure it out. Thank you so much in advance!
CodePudding user response:
In your 1st you can do cut
df['range'] = pd.cut(df.value,
bins = [0,54,70,180,250,np.inf],
labels = ['extreme low','low','in range','high','extreme high'])
For the 2nd
out = pd.crosstab(df['date'].dt.date, df['range']).reindex(categories, axis=1,fill_value=0).stack()
CodePudding user response:
Creating the Dataframe:
df = pd.DataFrame({
'date':['2022-05-01', '2022-05-01', '2022-05-02', '2022-05-02', '2022-05-03'],
'value': [120, 55, 230, 285, 41]
})
df.date = pd.to_datetime(df.date)
Categorizing range:
df['range'] = 'extreme low'
df['range'] = np.where((df.value>54) & (df.value<70),'low',df['range'])
df['range'] = np.where((df.value>=70) & (df.value<180),'in range',df['range'])
df['range'] = np.where((df.value>=180) & (df.value<250),'high',df['range'])
df['range'] = np.where((df.value>=250),'extreme high',df['range'])
Next, We first group by & for a new table:
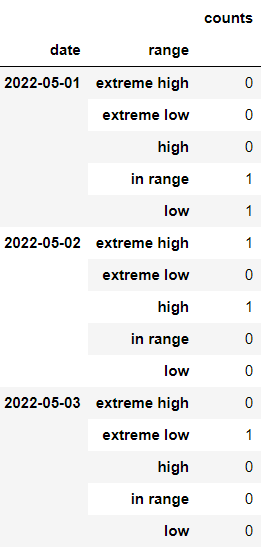
count_df = df.groupby(['date','range']).size().reset_index(name='counts')
You can finally pivot it to get counts of 0 items:
pd.pivot_table(count_df,
index=['date','range'],
values='counts',
fill_value = 0,
dropna=False,
aggfunc=np.sum)
Output: