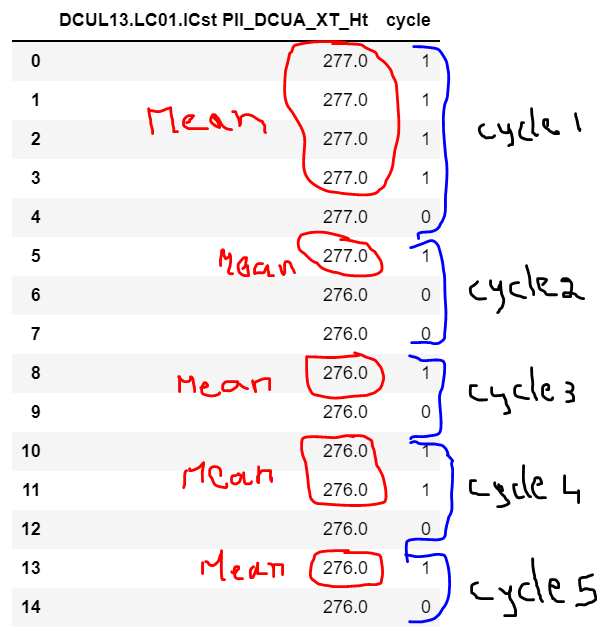
How can I calculate cycle-wise average (mean for values circled in red) only for true conditions (cycle value 1) for other column DCUL13.LC01? Is there any function or can someone help me with the code?
CodePudding user response:
You can aggregate mean for consecutive 1 create by cumulative sum and filtered with inverted mask by boolean indexing:
df = pd.DataFrame({'col' : range(15),'cycle' : [1,1,1,1,0,1,0,0,1,0,1,1,0,1,0]})
print (df)
col cycle
0 0 1
1 1 1
2 2 1
3 3 1
4 4 0
5 5 1
6 6 0
7 7 0
8 8 1
9 9 0
10 10 1
11 11 1
12 12 0
13 13 1
14 14 0
m = df['cycle'].eq(0)
df1 = df[~m].groupby(m.cumsum())['col'].mean().reset_index(name='Average')
print (df1)
cycle Average
0 0 1.5
1 1 5.0
2 3 8.0
3 4 10.5
4 5 13.0
Details:
print (df.assign(cumsum=m.cumsum(), inv_mask = ~m))
col cycle cumsum inv_mask
0 0 1 0 True
1 1 1 0 True
2 2 1 0 True
3 3 1 0 True
4 4 0 1 False
5 5 1 1 True
6 6 0 2 False
7 7 0 3 False
8 8 1 3 True
9 9 0 4 False
10 10 1 4 True
11 11 1 4 True
12 12 0 5 False
13 13 1 5 True
14 14 0 6 False
CodePudding user response:
I would rename your second column as it seems to not represent the cycle number but some other value (as shown by your annotations).
I would then create another column in your dataframe called cycle that contains the corresponding cycle number (e.g. in your case, 1 for the first 5 rows, 2 for the next 3 rows etc).
You can then use fancy indexing and the pandas groupby function to calculate the mean, as shown below (with renamed column names, only two cycles and slightly edited data so as to show the mean is being calculated correctly):
x = {'A' : [277, 277, 277, 277, 300, 277, 276, 276],
'B' : [1, 1, 1, 1, 0, 1, 0, 0],
'cycle' : [1, 1, 1, 1, 1, 2, 2, 2,]}
x = pd.DataFrame(x)
means_of_A = x[x['B']==1].groupby('cycle').mean()['A']
means_of_A is then equal to:
cycle
1 277.0
2 277.0
Name: A, dtype: float64
which is equivalent to what you need.