My dataframe has a column pairs that contains a key-pair list. Each key is unique in the list. e.g:
df = pd.DataFrame({
'id': ['1', '2', '3'],
'abc':None,
'pairs': [ ['abc/123', 'foo/345', 'xyz/789'], ['abc/456', 'foo/111', 'xyz/789'], ['xxx/222', 'foo/555', 'xyz/333'] ]
})
Dataframe is:
id | abc | pairs
------------------------------------
1 |None | [abc/123, foo/345, xyz/789]
2 |None | [abc/456, foo/111, xyz/789]
3 |None | [xxx/222, foo/555, xyz/333]
The column abc is filled with the value in column pairs if an element (idx=0) split by \ has the value (key) =='abc'.
Expected df:
id | abc | pairs
------------------------------------
1 |123 | [abc/123, foo/345, xyz/789]
2 |456 | [abc/456, foo/111, xyz/789]
3 |None | [xxx/222, foo/555, xyz/333]
I look for something like:
df.loc[df['pairs'].map(lambda x: 'abc' in (l.split('/')[0] for l in x)), 'abc'] = 'FOUND'
my problem is to replace the FOUND by the correct value the l.split('/')[0]
CodePudding user response:
You can use .str repeatedly:
df['abc'] = df['pairs'].str[0].str.split('/').loc[lambda x: x.str[0] == 'abc'].str[1]
Output:
>>> df
id abc pairs
0 1 123 [abc/123, foo/345, xyz/789]
1 2 456 [abc/456, foo/111, xyz/789]
2 3 NaN [xxx/222, foo/555, xyz/333]
More readable alternative:
x = df['pairs'].str[0].str.split('/')
df.loc[x.str[0] == 'abc', 'abc'] = x.str[1]
CodePudding user response:
Use str.get as much as you like ;)
s = df['pairs'].str.get(0).str.split('/')
df['abc'] = np.where(s.str.get(0) == 'abc', s.str.get(1), None)
CodePudding user response:
Try, you don't need apply nor lambda functions:
a = df['pairs'].str[0].str
df['abc'] = a.split('/').str[1].where(a.startswith('abc'))
Output:
id abc pairs
0 1 123 [abc/123, foo/345, xyz/789]
1 2 456 [abc/456, foo/111, xyz/789]
2 3 NaN [xxx/222, foo/555, xyz/333]
Note: str[0] is equal to using str.get(0).

CodePudding user response:
"You can use .str repeatedly" -> Yes, but… it is quite slow!
In this context, it is much better to use a list comprehension:
df['abc'] = [x[1] if (x:=l[0].split('/'))[0].startswith('abc') else float('nan')
for l in df['pairs']]
Rule of thumb: if you need 3 str or more, better try the list comprehension!
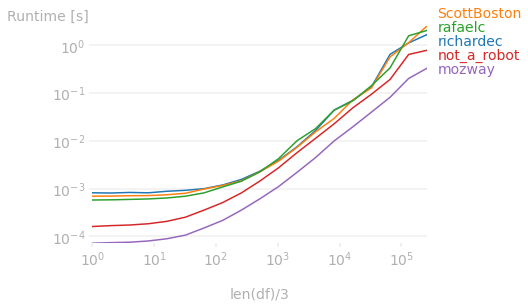
One picture is better than thousand words: test of the performance (all current answers) from 3 to almost 1M rows:
bonus: matching first "abc" on any position (not only 1st)
df['abc'] = [next((x.split('/')[1] for x in l if x.startswith('abc')), None)
for l in df['pairs']]