I would like to parse the following idx file: 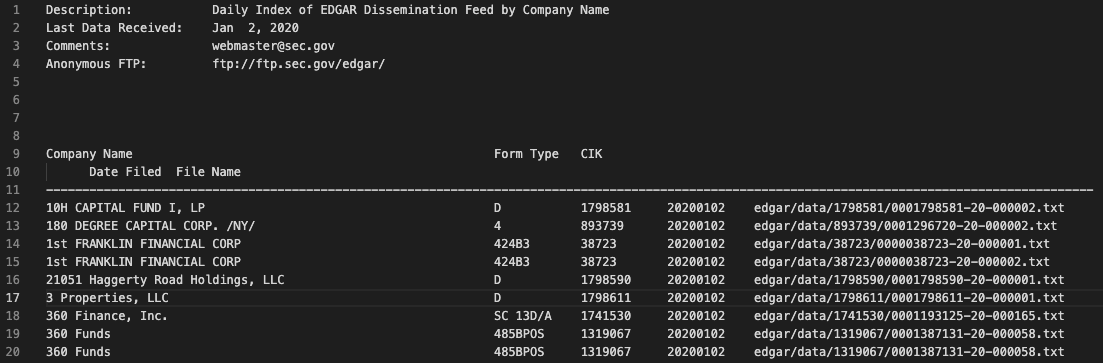
Next I would like to build a parser that is fault tollerance, because it should parse daily a new idx file into pd.DataFrame.
My idea was to use string manipulation, but it would be very complicated and not fault tollerance.
I would be thankful if someone can show the best practice to parse and give a boilerplate code.
CodePudding user response:
Since this is mostly a fixed width file you could use pandas read_fwf to read this file. You can skip over the leading information (via skiprows=) and get straight to the data. The column names are predefined and assigned when read:
idx_path = 'company.20220112.idx'
names = ['Company Name','Form Type','CIK','Date Filed','File Name']
df = pd.read_fwf(idx_path, colspecs=[(0,61),(62,74),(74,84),(86,94),(98,146)], names=names, skiprows=11)
df.head(10)
Company Name Form Type CIK Date Filed File Name
0 005 - Series of IPOSharks Venture Master Fund,... D 1888451 20220112 edgar/data/1888451/0001888451-22-000002.txt
1 10X Capital Venture Acquisition Corp. III EFFECT 1848948 20220111 edgar/data/1848948/9999999995-22-000102.txt
2 110 White Partners LLC D 1903845 20220112 edgar/data/1903845/0001884293-22-000001.txt
3 15 Beach, MHC 3 1903509 20220112 edgar/data/1903509/0001567619-22-001073.txt
4 15 Beach, MHC SC 13D 1903509 20220112 edgar/data/1903509/0000943374-22-000014.txt
5 170 Valley LLC D 1903913 20220112 edgar/data/1903913/0001903913-22-000001.txt
6 1st FRANKLIN FINANCIAL CORP 424B3 38723 20220112 edgar/data/38723/0000038723-22-000003.txt
7 1st FRANKLIN FINANCIAL CORP 424B3 38723 20220112 edgar/data/38723/0000038723-22-000004.txt
8 215 BF Associates LLC D 1904145 20220112 edgar/data/1904145/0001904145-22-000001.txt
9 2401 Midpoint Drive REIT, LLC D 1903337 20220112 edgar/data/1903337/0001903337-22-000001.txt