I have a table with below values:-
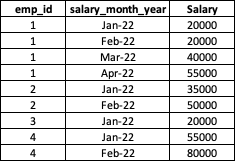
I want to write a code in python/pyspark where I need to find the employee code who got the increment 20% or more than that. Also, I need how many times he got the increment.
CodePudding user response:
Use Window functions.
w=Window.partitionBy('emp_id').orderBy(to_date('salary_month_year'))
df1 = (df.withColumn('new_salary',lag('salary').over(w)).fillna(0)#Find previous salary in each row
.withColumn('%increase', when(col('new_salary')==0,0)
.otherwise(round((col('salary')-col('new_salary'))/col('salary'),1)*100))#Where group starts make it 0, and rest compute increment
.withColumn('incr_count',sum((col("%increase")>0).cast('int')).over(w))#Compute increment count
.where(col("%increase")>20).drop('new_salary')#Filter where salary >20% and drop unwanted column
).show()
------ ----------------- ------ --------- ----------
|emp_id|salary_month_year|salary|%increase|incr_count|
------ ----------------- ------ --------- ----------
| 1| Mar-22| 400| 50.0| 2|
| 1| Apr-22| 550| 30.0| 2|
| 2| Feb-22| 500| 30.0| 1|
| 4| Feb-22| 800| 30.0| 1|
------ ----------------- ------ --------- ----------