The code below gets the html data into a list. I am trying to scrape a specific element called data-append-csv (example is: data-append-csv="abbotco01") from the baseball reference page html link (see the code for the link):
Current Code:
from bs4 import BeautifulSoup
from bs4 import Comment
import pandas as pd
import os.path
import requests
r = requests.get("https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml")
soup = BeautifulSoup(r.content, "html.parser") # try lxml
[x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x]
Current Environment Settings:
dependencies:
- python=3.9.7
- beautifulsoup4=4.11.1
- jupyterlab=3.3.2
- pandas=1.4.2
- pyodbc=4.0.32
The end goal: Be able to have a pandas dataframe that has each element of data-append-csv from the html table.
| index | data-append-csv |
|---|---|
| 0 | abbotco01 |
| 1 | abreual01 |
| 2 | abreubr01 |
etc.
CodePudding user response:
You should be able to get the table with this:
import requests
from bs4 import BeautifulSoup
from bs4 import Comment
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:101.0) Gecko/20100101 Firefox/101.0"
}
url = "https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml"
with requests.Session() as s:
comments = (
BeautifulSoup(
s.get(url, headers=headers).text,
"lxml"
).find_all(string=lambda text: isinstance(text, Comment))
)
table = pd.concat(
pd.read_html(
[c for c in comments if "players_standard_batting" in c][0]
)
)
print(table)
table.to_csv("batting.csv", index=False)
Output:
Rk Name Age Tm Lg ... HBP SH SF IBB Pos Summary
0 1 Fernando Abad* 35 BAL AL ... 0 0 0 0 1
1 2 Cory Abbott 25 CHC NL ... 0 0 0 0 /1H
2 3 Albert Abreu 25 NYY AL ... 0 0 0 0 1
3 4 Bryan Abreu 24 HOU AL ... 0 0 0 0 1
4 5 José Abreu 34 CHW AL ... 22 0 10 3 *3D/5
... ... ... ... ... ... ... .. .. .. .. ...
1787 1720 Bruce Zimmermann* 26 BAL AL ... 0 0 0 0 1
1788 1721 Jordan Zimmermann 35 MIL NL ... 0 0 0 0 /1
1789 1722 Tyler Zuber 26 KCR AL ... 0 0 0 0 1
1790 1723 Mike Zunino 30 TBR AL ... 7 0 1 0 2/H
1791 NaN LgAvg per 600 PA NaN NaN NaN ... 7 2 4 2 NaN
[1792 rows x 30 columns]
And the csv uploaded:
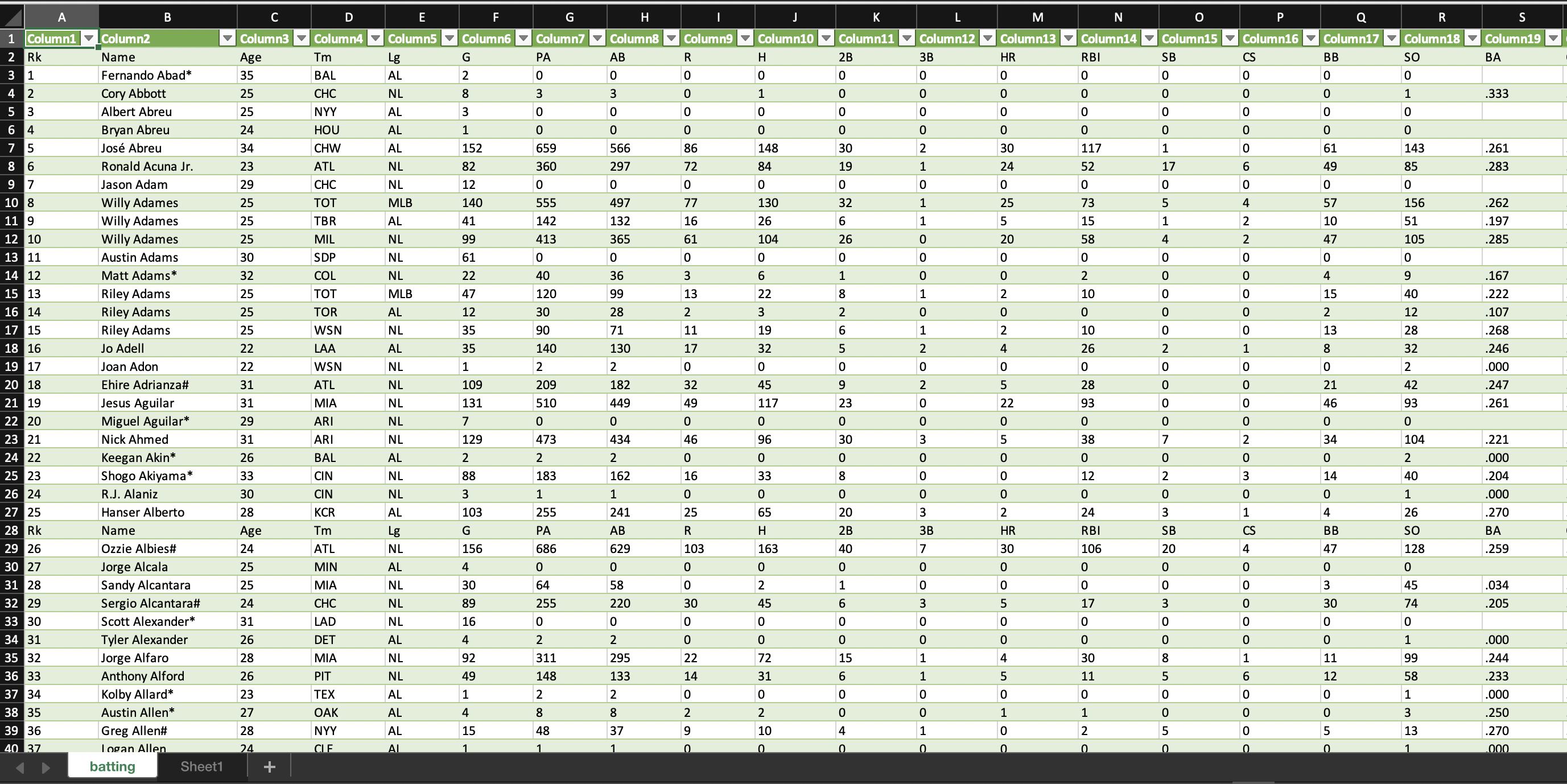
CodePudding user response:
First convert the string into an BeautifulSoup object and .select('[data-append-csv]'):
table = [x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x][0]
[(a.find_previous('th').text,a.get('data-append-csv')) for a in BeautifulSoup(table).select('[data-append-csv]')]
To ensure a correct join to your original data, try to scrape the rank as well in case that there is are rows without these attribute and the length of both dataframes will be different:
(a.find_previous('th').text,a.get('data-append-csv'))
Now you could create your dataframe from your list:
pd.DataFrame([(a.find_previous('th').text,a.get('data-append-csv')) for a in BeautifulSoup(table).select('[data-append-csv]')],columns=['Rk','data-append-csv'],dtype='object')
Example
Join your data to your initial dataframe and check last column:
from bs4 import BeautifulSoup
from bs4 import Comment
import pandas as pd
import requests
r = requests.get("https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml")
soup = BeautifulSoup(r.text)
table = [x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x][0]
### create and clean dataframe 1
df1 = pd.read_html(table)[0]
df1 = df1[(~df1.Rk.isna()) & (df1.Rk != 'Rk')]
df1.set_index('Rk', inplace=True)
### create and clean dataframe 2
df2 = pd.DataFrame([(a.find_previous('th').text,a.get('data-append-csv')) for a in BeautifulSoup(table).select('[data-append-csv]')],columns=['Rk','data-append-csv'],dtype='object')
df2.set_index('Rk', inplace=True)
### join both dataframe
df1.join(df2).reset_index()
Output
| Rk | Name | Age | Tm | Lg | G | PA | AB | R | H | 2B | 3B | HR | RBI | SB | CS | BB | SO | BA | OBP | SLG | OPS | OPS | TB | GDP | HBP | SH | SF | IBB | Pos Summary | data-append-csv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Fernando Abad* | 35 | BAL | AL | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | nan | nan | nan | nan | nan | 0 | 0 | 0 | 0 | 0 | 0 | 1 | abadfe01 |
| 1 | 2 | Cory Abbott | 25 | CHC | NL | 8 | 3 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.333 | 0.333 | 0.333 | 0.667 | 81 | 1 | 0 | 0 | 0 | 0 | 0 | /1H | abbotco01 |
| 2 | 3 | Albert Abreu | 25 | NYY | AL | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | nan | nan | nan | nan | nan | 0 | 0 | 0 | 0 | 0 | 0 | 1 | abreual01 |
| 3 | 4 | Bryan Abreu | 24 | HOU | AL | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | nan | nan | nan | nan | nan | 0 | 0 | 0 | 0 | 0 | 0 | 1 | abreubr01 |
| 4 | 5 | José Abreu | 34 | CHW | AL | 152 | 659 | 566 | 86 | 148 | 30 | 2 | 30 | 117 | 1 | 0 | 61 | 143 | 0.261 | 0.351 | 0.481 | 0.831 | 124 | 272 | 28 | 22 | 0 | 10 | 3 | *3D/5 | abreujo02 |
....
CodePudding user response:
You need to convert the html comment you extracted and parse it using BeautifulSoup,
then use CSS selector to get the rows with the 'data-append-csv' in its attributes.
import requests
import pandas as pd
from bs4 import Comment, BeautifulSoup
r = requests.get("https://www.baseball-reference.com/leagues/majors/2021-standard-batting.shtml")
soup = BeautifulSoup(r.content, 'html.parser')
table_txt = [x.extract() for x in soup.find_all(string=lambda text: isinstance(text, Comment)) if 'id="div_players_standard_batting"' in x][0]
table_soup = BeautifulSoup(table_txt, 'html.parser')
list_ = [{'index':index, 'data-append-csv':player['data-append-csv']} for index, player in enumerate(table_soup.select('td[data-append-csv]'), start=1)]
df = pd.DataFrame(list_)