I try to create simple DSL with Python 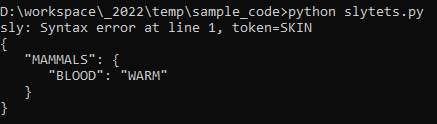
result of executing :
sly: Syntax error at line 1, token=SKIN
{
"MAMMALS": {
"BLOOD": "WARM"
}
}
I guess I have to edit the Parser, but I can't think how, and would appreciate any pointers you can give me.
CodePudding user response:
You have non-terminals named animals, animaldetails, and animalnameddetails, in plural, which would normally lead one to expect that the grammar for each of them would allow a sequence of things. But they don't. Each of these categories parses a single thing. You've implemented the singular, and although it's named in plural, there's no repetition.
That this was not your intent is evident from your example, which does have multiple sections and multiple attributes in each section. But since the grammar only describes one attribute and value, the second one is a syntax error.
Traditionally, grammars will implement sequences with pairs of non-terminals; a singular non-terminal which describes a single thing, and a plural non-terminal which describes how lists are formed (simple concatenation, or separated by punctuation). So you might have:
file: sections
sections: empty
| sections section
section: category attributes
settings: empty
| settings setting
setting: attribute '=' value
You probably should also look fora description of how to manage semantic values. Storing intermediate results in class members, as you do, works only when the grammar doesn't allow nesting, which is relatively unusual. It's a technique which will almost always get you into trouble. The semantic actions of each production should manage these values:
- A singular object syntax should create and return a representation of the object.
- A plural→empty production should create and return a representation of an empty collection.
- Similarly, a production of the form things→ things thing should append the new thing to the aggregate of things, and then return the augmented aggregate.
CodePudding user response:
Cheers...
from json import dumps
from sly import Lexer, Parser
class MyLexer(Lexer):
tokens = {ANIMALS, ANIMAL_NAME, BLOOD, SKIN, BREATHE, ASSIGN, ASSIGN_VALUE}
ignore = ' \t'
ANIMALS = r'ANIMALS'
BLOOD = r'BLOOD'
SKIN = r'SKIN'
BREATHE = r'BREATHE'
ASSIGN = r'='
ASSIGN_VALUE = r'[a-zA-Z_][a-zA-Z0-9_]*'
@_(r'\{[a-zA-Z_][a-zA-Z0-9_]*\}')
def ANIMAL_NAME(self, t):
t.value = str(t.value).lstrip('{').rstrip('}')
return t
@_(r'\n ')
def NEWLINE(self, t):
self.lineno = t.value.count('\n')
class MyParser(Parser):
tokens = MyLexer.tokens
def __init__(self):
self.__config = {}
def __del__(self):
print(dumps(self.__config, indent=4))
@_('ANIMALS animal animal')
def animals(self, p):
pass
@_('ANIMAL_NAME assignment assignment assignment')
def animal(self, p):
if p.ANIMAL_NAME not in self.__config:
self.__config[p.ANIMAL_NAME] = {}
animal_name, *assignments = p._slice
for assignment in assignments:
assignment_key, assignment_value = assignment.value
self.__config[p.ANIMAL_NAME][assignment_key] = assignment_value
@_('key ASSIGN ASSIGN_VALUE')
def assignment(self, p):
return p.key, p.ASSIGN_VALUE
@_('BLOOD', 'SKIN', 'BREATHE')
def key(self, p):
return p[0]
if __name__ == '__main__':
lexer = MyLexer()
parser = MyParser()
text = '''ANIMALS
{MAMMALS}
BLOOD = WARM
SKIN = FUR
BREATHE = LUNGS
{FISH}
BLOOD = COLD
SKIN = SCALY
BREATHE = GILLS
'''
parser.parse(lexer.tokenize(text))
Output:
{
"MAMMALS": {
"BLOOD": "WARM",
"SKIN": "FUR",
"BREATHE": "LUNGS"
},
"FISH": {
"BLOOD": "COLD",
"SKIN": "SCALY",
"BREATHE": "GILLS"
}
}