I have a BIG dataframe with millions of rows & many columns and need to do GROUPBY AND COUNT OF VALUES OF DIFFERENT COLUMNS .
Need help with efficient coding for the problem with minimal lines of code and a code which runs very fast.
I'm giving a simpler example below about my problem.
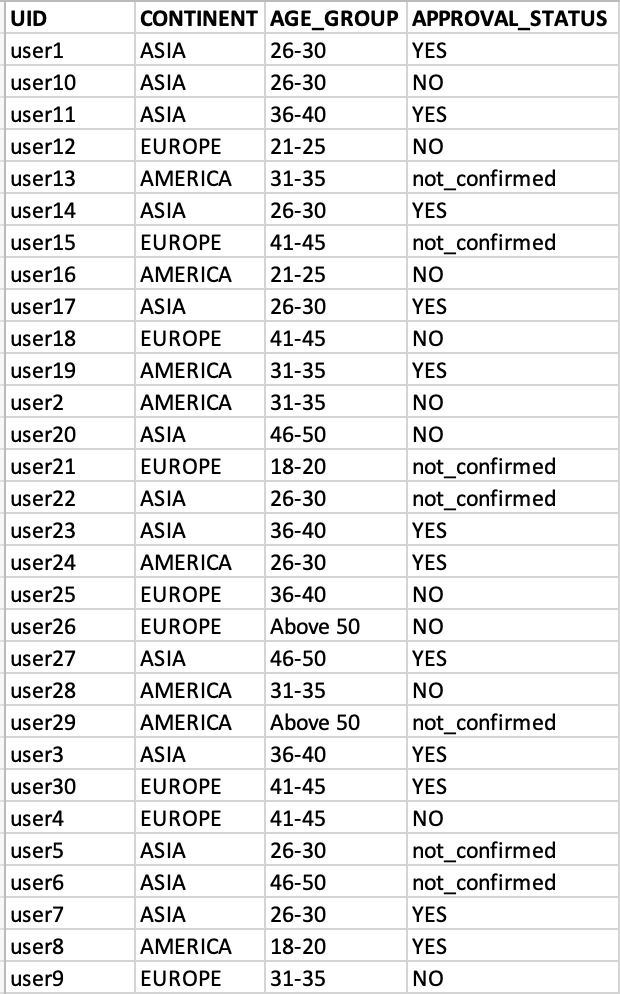
Below is my input CSV.
UID,CONTINENT,AGE_GROUP,APPROVAL_STATUS
user1,ASIA,26-30,YES
user10,ASIA,26-30,NO
user11,ASIA,36-40,YES
user12,EUROPE,21-25,NO
user13,AMERICA,31-35,not_confirmed
user14,ASIA,26-30,YES
user15,EUROPE,41-45,not_confirmed
user16,AMERICA,21-25,NO
user17,ASIA,26-30,YES
user18,EUROPE,41-45,NO
user19,AMERICA,31-35,YES
user2,AMERICA,31-35,NO
user20,ASIA,46-50,NO
user21,EUROPE,18-20,not_confirmed
user22,ASIA,26-30,not_confirmed
user23,ASIA,36-40,YES
user24,AMERICA,26-30,YES
user25,EUROPE,36-40,NO
user26,EUROPE,Above 50,NO
user27,ASIA,46-50,YES
user28,AMERICA,31-35,NO
user29,AMERICA,Above 50,not_confirmed
user3,ASIA,36-40,YES
user30,EUROPE,41-45,YES
user4,EUROPE,41-45,NO
user5,ASIA,26-30,not_confirmed
user6,ASIA,46-50,not_confirmed
user7,ASIA,26-30,YES
user8,AMERICA,18-20,YES
user9,EUROPE,31-35,NO
I Expect the output to be as below. Output should show
- CONTINENT column as the main groupby column
- UNIQUE values of AGE_GROUP and APPROVAL_STATUS columns as separate column name. And also, it should display the count of UNIQUE values of AGE_GROUP and APPROVAL_STATUS columns for each CONTINENT under respective output columns.
Output:-
CONTINENT,18-20,21-25,26-30,31-35,36-40,41-45,46-50,Above 50,NO,YES,not_confirmed,USER_COUNT
AMERICA,1,1,1,4,0,0,0,1,3,3,2,8
ASIA,0,0,7,0,3,0,3,0,2,8,3,13
EUROPE,1,1,0,1,1,4,0,1,6,1,2,9

Below is how I'm achieving it currently, but this is NOT en efficient way. Need help with efficient coding for the problem with minimal lines of code and a code which runs very fast. I've also sen that this could be achieved by using pivit table with pandas. But not too sure about it.
in_file = "/Users/user1/groupby.csv"
out_file = "/Users/user1/groupby1.csv"
df= pd.read_csv(in_file)
print(df)
df1 = df.groupby(['CONTINENT', 'AGE_GROUP']).size().unstack(fill_value=0).reset_index()
df1 = df1.sort_values(["CONTINENT"], axis=0, ascending=True)
print(df1)
df2 = df.groupby(['CONTINENT', 'APPROVAL_STATUS']).size().unstack(fill_value=0).reset_index()
df2 = df2.sort_values(["CONTINENT"], axis=0, ascending=True)
print(df2)
df3 = df.groupby("CONTINENT").count().reset_index()
df3 = df3[df3.columns[0:2]]
df3.columns = ["CONTINENT", "USER_COUNT"]
df3 = df3.sort_values(["CONTINENT"], axis=0, ascending=True)
df3.reset_index(drop=True, inplace=True)
# df3.to_csv(out_file, index=False)
print(df3)
df2.drop('CONTINENT', axis=1, inplace=True)
df3.drop('CONTINENT', axis=1, inplace=True)
df_final = pd.concat([df1, df2, df3], axis=1)
print(df_final)
df_final.to_csv(out_file, index=False)
CodePudding user response:
Easy solution
Let us use crosstabs to calculate frequency tables then concat the tables along columns axis:
s1 = pd.crosstab(df['CONTINENT'], df['AGE_GROUP'])
s2 = pd.crosstab(df['CONTINENT'], df['APPROVAL_STATUS'])
pd.concat([s1, s2, s2.sum(1).rename('USER_COUNT')], axis=1)
18-20 21-25 26-30 31-35 36-40 41-45 46-50 Above 50 NO YES not_confirmed USER_COUNT
CONTINENT
AMERICA 1 1 1 4 0 0 0 1 3 3 2 8
ASIA 0 0 7 0 3 0 3 0 2 8 3 13
EUROPE 1 1 0 1 1 4 0 1 6 1 2 9