I have two dataframes, one that contains a large amount of textual data scraped from PDF documents, and another that contains categories and subcategories.
For each subcategory, I need to calculate the percentage of documents that contains at least one mention of the subcategory (e.g. for the subcategory "apple", calculate the percentage of documents that contains "apple"). I'm able to correctly calculate the subcategory percentage. However, when I attempt to populate the dataframe with the value, an incorrect value is displayed.
For each category, I need to calculate the percentage of documents that contains at least one mention of each subcategory (e.g. for the category "fruit", calculate the percentage of documents that contains "apple" or "banana"). The calculation of this value is harder, as it's not a subtotal. I'm trying to calcuate this value through a combination of GROUPBY and APPLY, but I've gotten stuck.
The document dataframe looks like this:

The categories dataframe looks like this:

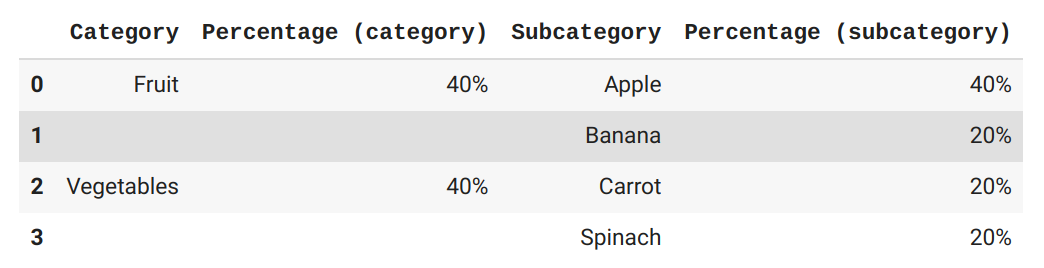
This is what I'm aiming for:
This is what I have so far:
import pandas as pd
documents = {'Text': ['apple apple', 'banana apple', 'carrot carrot carrot', 'spinach','hammer']}
doc_df = pd.DataFrame(data=documents)
print(doc_df,'\n')
categories = {'Category': ['fruit', 'fruit', 'vegetable', 'vegetable'],
'Subcategory': ['apple', 'banana', 'carrot', 'spinach']}
cat_df = pd.DataFrame(data=categories)
print(cat_df,'\n')
total_docs = doc_df.shape[0]
cat_df['Subcat_Percentage'] = 0
cat_df['Cat_Percentage'] = 0
cat_df = cat_df[['Category', 'Cat_Percentage', 'Subcategory', 'Subcat_Percentage']]
for idx, subcategory in enumerate(cat_df['Subcategory']):
total_docs_with_subcat = doc_df[doc_df['Text'].str.contains(subcategory)].shape[0]
subcat_percentage = total_docs_with_subcat / total_docs #calculation is correct
cat_df.at[idx, 'Subcat_Percentage'] = subcat_percentage #wrong value is output
cat_percentage = cat_df.groupby('Category').apply(lambda x: (doc_df[doc_df['Text'].str.contains(subcategory)].shape[0]) #this doesn't work
cat_df.at[idx, 'Cat_Percentage'] = cat_percentage
print('\n', cat_df,'\n')
CodePudding user response:
It Could be better optimized, but try this :
agg_category = cat_df.groupby('Category')['Subcategory'].agg('|'.join)
def percentage_cat(category):
return doc_df[doc_df['Text'].str.contains(agg_category[category])].size / doc_df.size
def percentage_subcat(subcategory):
return doc_df[doc_df['Text'].str.contains(subcategory)].size / doc_df.size
cat_df['percentage_category'] = cat_df['Category'].apply(percentage_cat)
cat_df['sub_percentage'] = cat_df['Subcategory'].apply(percentage_subcat)
cat_df