I have a dataframe 'merged_df' that looks like this -
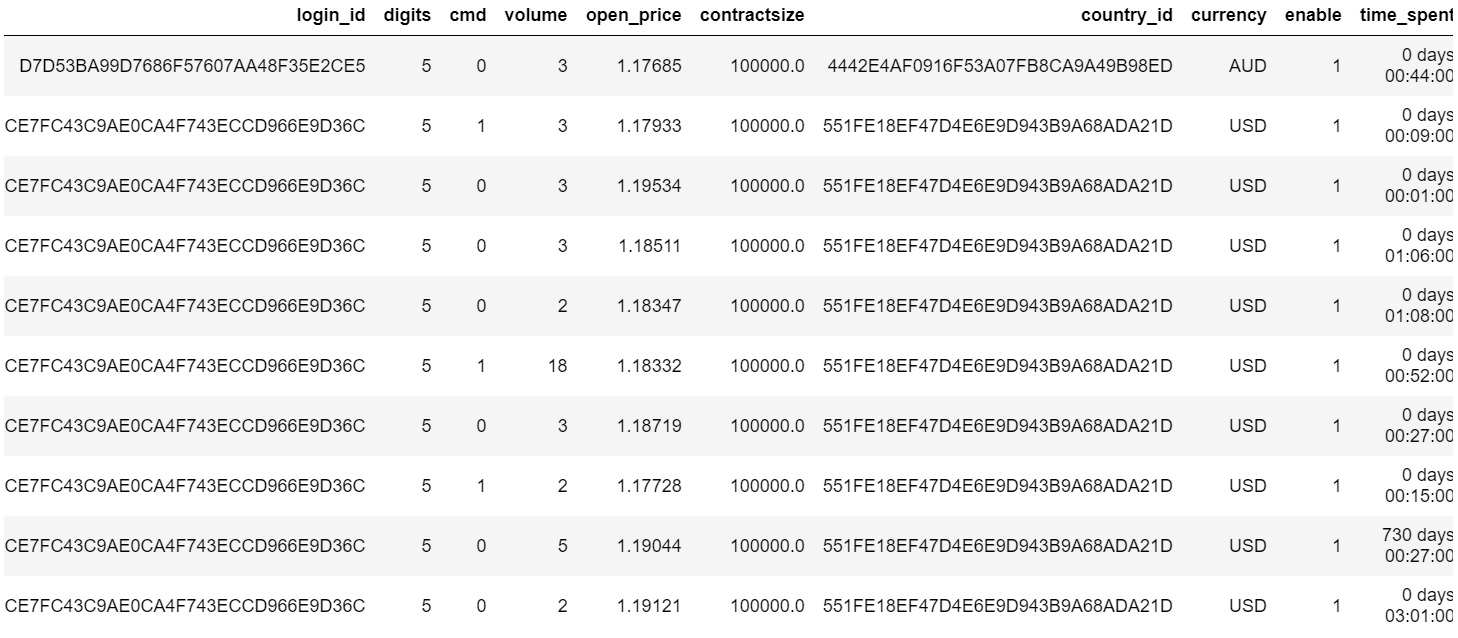
It has many duplicates in 'login_id' column and in enable column the values are 0s and 1s
Find the percentage of unique login_id that has enable value = 1
CodePudding user response:
You can remove the duplicates in login_id by doing the following:
no_duplicates = merged_df.drop_duplicates(subset="login_id")
Then you can calulate the desired percentage:
percentage = (len(no_duplicates[no_duplicates["enable"] == 1]) / len(no_duplicates)) * 100