I got problems when processing data in an xlsx file. my leader told me first to merge the same rows' values according to uid. then I should get the sum of "content post volume", "views" and "exploration volume" according to the column "Account type" which consists of types "content" and "social".
For example, there are two rows recording the data of uid 1680260000, now merge them into one. the later three columns should add, turn into 5364, 3710029, and 300478. But don't modify the former three columns. The user_level should keep it as F2.(order like F1, F2, F3, F4...prefer the front value)
uid user_level Account type content post volum exploration volum Views
1680260000 F2 content 112 934318 118
2209220000 F1 social 628 147623896 20160351
1680260000 F5 content 5252 2775711 300290
5390800000 F3 content 127 1235530 8554
6017200000 F2 social 142 649046 43144
7054610000 F2 social 23 1226520 232074
1682390000 F2 content 1162 18025639 722
3136670000 F2 content 6 2123571 189379
3136670000 F6 content 0 6 0
5393860000 F2 social 60 3246476 17
6017200000 F3 content 677 8855471 277229
6017200000 F2 social 737 11854463 0
1685250000 F2 content 96 2211002 5942
The expected result:
uid user_level Account type content post volum exploration volum Views
1680260000 F2 content 5364 3710029 20160469
2209220000 F1 social 628 147623896 20160351
5390800000 F3 content 127 1235530 8554
6017200000 F2 social 1556 21358980 320373
7054610000 F2 social 23 1226520 232074
1682390000 F2 content 1162 18025639 722
3136670000 F2 content 6 2123577 189379
5393860000 F2 social 60 3246476 17
1685250000 F2 content 96 2211002 5942
Now the problem is if I use df.groupby("uid").sum(), the column "Account type"(which type is string) will add together too. This isn't what I want, because later I need to extract data depending on it. For example, after I merge the rows with duplicated uid, I need to get rows which "Account type" is in ["F0", "F1", "F2"]. But groupby will make cell value turn to "F1F3", "F4F1" so it's hard to distinguish it. I did try to split the string when extracting, such as
file[file.Account_social_type.str.split("F").isin(["1", "2", "3"])]
ps: after df.str.split("F"), the "F1F3" will turn to ["1", "3"]
but somehow at this time .str.split("F") won't work for every cell but the whole column!
So in the last, I use a stupid method. First I use
taruid = file[file.uid.duplicated(keep="first")].uid.to_list()
# somehow this statement still left repeated value in list ^
taruid = list(set(taruid))
to get all repeated uid. Then use
def changeOne(rows : pd.DataFrame):
rows = rows.sort_values(by = "F_level")
rows.content_post_volume.iloc[0] = rows["content_post_volume"].sum()/(92)
rows.views.iloc[0] = rows["views"].sum()/92
rows.exploration_volume.iloc[0] = rows["exploration_volume"].sum()/92
return rows
replaceOne : pd.DataFrame = pd.DataFrame()
for items in taruid:
goals = file[file.uid == items]
replaceOne = replaceOne.append(changeOne(goals.copy()).iloc[0])
to get the sum value of specified columns and store it in the first rows. in the last use
file = file.drop_duplicates(subset = "uid", keep=False)
# drop all repeated rows
file = pd.concat([file, replaceOne], axis=0, ignore_index=True)
to get the final integrated data. And the flaws are very significant, near 1500 data cost 3s. There must be a much easier and more efficient method to use groupby or some advanced pandas function to slove this problem.
WHAT I WANNA ask is, how can we merge/add duplicated/specified rows without modify string column or the columns I specified.
I spend half a day to optimize this but I failed, really appreciate it if you guys can figure it out.
CodePudding user response:
The expected format is unclear, but you can use different functions to aggregate the data.
Let's form comma separated strings of the unique values for "user_level" and "Account type":
string_agg = lambda s: ','.join(dict.fromkeys(s))
out = (df.groupby('uid', as_index=False)
.agg({'user_level': string_agg, 'Account type': string_agg,
'content post volum': 'sum',
'exploration volum': 'sum', 'Views': 'sum'})
)
Output:
uid user_level Account type content post volum exploration volum Views
0 1680260000 F2,F5 content 5364 3710029 300408
1 1682390000 F2 content 1162 18025639 722
2 1685250000 F2 content 96 2211002 5942
3 2209220000 F1 social 628 147623896 20160351
4 3136670000 F2,F6 content 6 2123577 189379
5 5390800000 F3 content 127 1235530 8554
6 5393860000 F2 social 60 3246476
7 6017200000 F2,F3 social,content 1556 21358980 320373
8 7054610000 F2 social 23 1226520 232074
For the demo, here is an alternative aggregation function to count the duplicates:
from collections import Counter
string_agg = lambda s: ','.join([f'{k}({v})' if v>1 else k for k,v in Counter(s).items()])
Output:
uid user_level Account type content post volum exploration volum Views
0 1680260000 F2,F5 content(2) 5364 3710029 300408
1 1682390000 F2 content 1162 18025639 722
2 1685250000 F2 content 96 2211002 5942
3 2209220000 F1 social 628 147623896 20160351
4 3136670000 F2,F6 content(2) 6 2123577 189379
5 5390800000 F3 content 127
6 5393860000 F2 social 60 3246476 17
7 6017200000 F2(2),F3 social(2),content 1556 21358980 320373
8 7054610000 F2 social 23 1226520 232074
CodePudding user response:
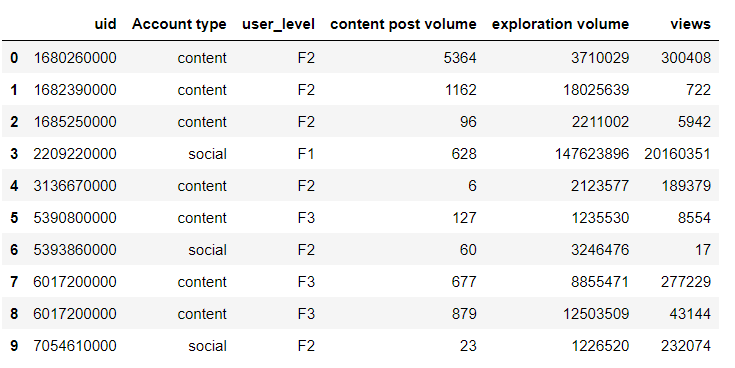
df = df.groupby(['uid','Account type', 'user_level '])[['content post volume', 'exploration volume', 'views']].sum()
df2 = df.groupby(['uid','Account type'])[['content post volume', 'exploration volume', 'views']].sum()
df = df.reset_index()
df = df.drop_duplicates('uid')
df = df[['uid', 'Account type', 'user_level ']]
df = df.merge(df2, on=['uid'])
df
output