I am struggling to find the sum of count column based on subtring present in a column Name. The substring should co exist with the other multiple values present in another column that is Error Name. If substring (e.g. Ehsan) matches and another column i.e. Error Name has those multiple values (Device and Line Error) then i would some the count in Count Column. Remember I have to sum only those count which has substring Ehsan in Name and Device and Line Error in Error Name Below is my Raw Data:
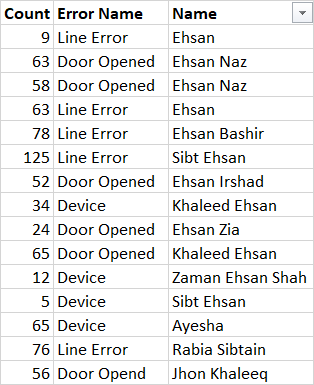
And my output should look like this:
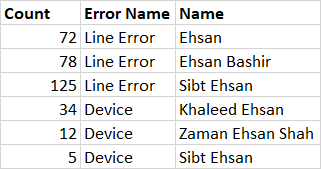
Please needful help is required, thanks
CodePudding user response:
After Editing The Question:
You need to select rows that contain Ehsan and then use pandas.groupby on the result dataframe like below:
mask_name = df['Name'].str.contains(r'.*(?:Ehsan).*')
mask_err = df['Error Name'].str.contains(r'(?:\bLine Error\b|\bDevice\b)')
df = df[mask_name & mask_err]
df.groupby(['Name', 'Error Name'])['Count'].sum().reset_index()
Before Editing The Question:
You can write a mask for columns Name and Error Name with regex then select rows that have True in two masks and sum Count for those rows with pandas.loc and pandas.sum like below:
mask_name = df['Name'].str.contains(r'.*(?:Ehsan).*')
mask_err = df['Error Name'].str.contains(r'(?:\bLine Error\b|\bDevice\b)')
df.loc[mask_name & mask_err, 'Count'].sum()
CodePudding user response:
We can use str.contains and sum here:
total = df[df["Name"].str.contains(r'\bEhsan\b', flags=re.I, na=False, regex=True)]["Count"].sum()