I tried to save a PySpark dataframe in a SQL database in Synapse:
test = spark.createDataFrame([Row("Sarah", 28), Row("Anne", 5)], ["Name", "Age"])
test.write\
.format("jdbc")\
.option("url", "jdbc:sqlserver://XXXX.sql.azuresynapse.net:1433;database=azlsynddap001;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;Authentication=ActiveDirectoryIntegrated")\
.option("forwardSparkAzureStorageCredentials", "true")\
.option("dbTable", "test_CP")\
.save()
I got the following error:
IllegalArgumentException: KrbException: Cannot locate default realm
Here is the detail of the error:
---------------------------------------------------------------------------
IllegalArgumentException Traceback (most recent call last)
/tmp/ipykernel_7675/2619697817.py in <module>
1 test = spark.createDataFrame([Row("Sarah", 28), Row("Anne", 5)], ["Name", "Age"])
----> 2 test.write\
3 .format("jdbc")\
4 .option("url", "jdbc:sqlserver://XXXX.sql.azuresynapse.net:1433;database=XXXX;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;Authentication=ActiveDirectoryIntegrated")\
5 .option("forwardSparkAzureStorageCredentials", "true")\
/opt/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py in save(self, path, format, mode, partitionBy, **options)
1105 self.format(format)
1106 if path is None:
-> 1107 self._jwrite.save()
1108 else:
1109 self._jwrite.save(path)
~/cluster-env/env/lib/python3.8/site-packages/py4j/java_gateway.py in __call__(self, *args)
1302
1303 answer = self.gateway_client.send_command(command)
-> 1304 return_value = get_return_value(
1305 answer, self.gateway_client, self.target_id, self.name)
1306
/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py in deco(*a, **kw)
115 # Hide where the exception came from that shows a non-Pythonic
116 # JVM exception message.
--> 117 raise converted from None
118 else:
119 raise
IllegalArgumentException: KrbException: Cannot locate default realm
Where does this error come from? I googled everywhere but no way to find what I did wrong. I also see this 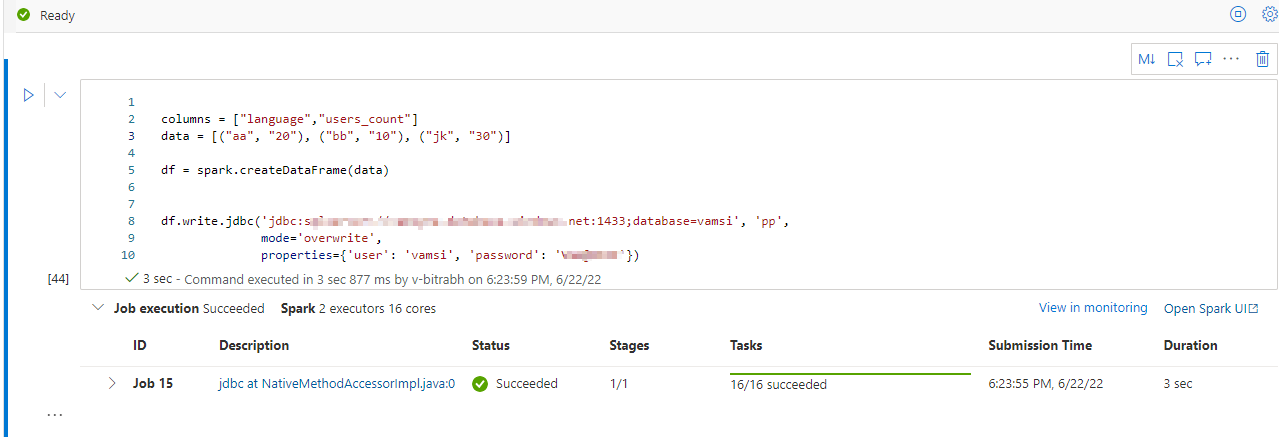
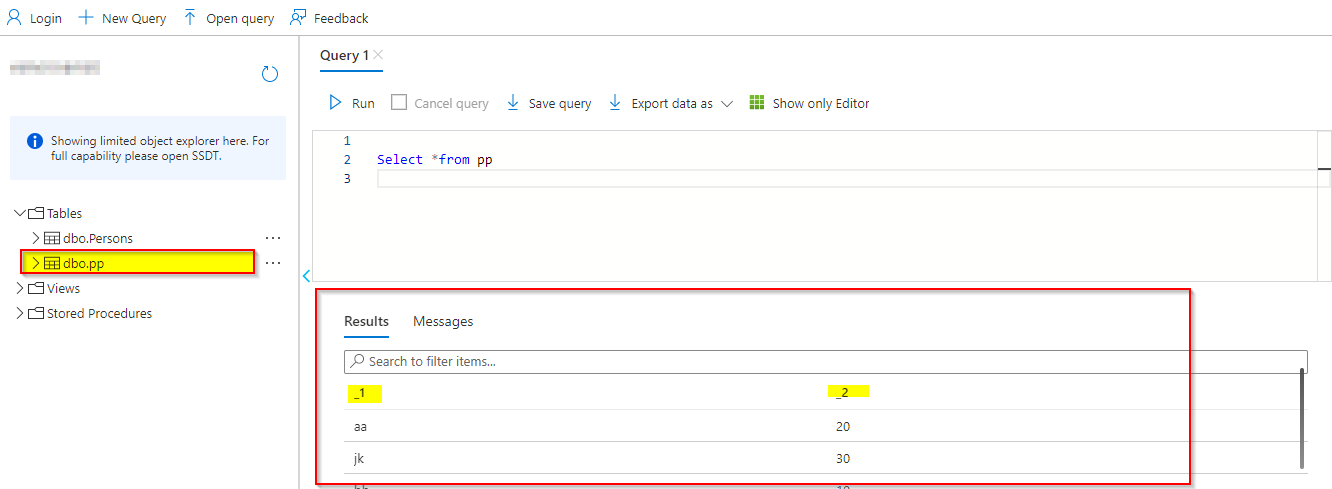
Output:
CodePudding user response:
Can you try using a dedicated synapse connector instead of JDBC, more details here
Also if you are using databricks then you can try using databricks SQL DW connector details here