I have a list of dictionary like this, wanted to load this into a data frame for a couple of Keys in the object.
The data frame I would like looks like
ID -- retweet_count -- favorite_count
tweet_list = ['{"created_at": "Tue Aug 01 00:17:27 0000 2017", "id": 892177421306343426, "id_str": "892177421306343426", "full_text": "This is Tilly. She\'s just checking pup on you.", "truncated": false, "display_text_range": [0, 138], "contributors": null, "is_quote_status": false, "retweet_count": 6514, "favorite_count": 33819, "favorited": false, "retweeted": false, "possibly_sensitive": false, "possibly_sensitive_appealable": false, "lang": "en"}',
'{"created_at": "Sun Jul 30 15:58:51 0000 2017", "id": 891689557279858688, "id_str": "891689557279858688", "full_text": "This is Darla. She commenced a snooze mid meal.", "truncated": false, "display_text_range": [0, 79], "entities": {"hashtags": [], "symbols": [], "following": true, "follow_request_sent": false, "notifications": false, "translator_type": "none"}, "geo": null, "coordinates": null, "place": null, "contributors": null, "is_quote_status": false, "retweet_count": 8964, "favorite_count": 42908, "favorited": false, "retweeted": false, "possibly_sensitive": false, "possibly_sensitive_appealable": false, "lang": "en"}']
CodePudding user response:
You need to have a reporoducible data first:
new_list = [
{"created_at": "Tue Aug 01 00:17:27 0000 2017",
"id": 892177421306343426,
"id_str": "892177421306343426",
"full_text": "This is Tilly. She\'s just checking pup on you.",
"truncated": False,
"display_text_range": [0, 138],
"contributors": None,
"is_quote_status": False,
"retweet_count": 6514,
"favorite_count": 33819,
"favorited": False,
"retweeted": False,
"possibly_sensitive": False,
"possibly_sensitive_appealable": False,
"lang": "en"},
{"created_at": "Sun Jul 30 15:58:51 0000 2017",
"id": 891689557279858688,
"id_str": "891689557279858688",
"full_text": "This is Darla. She commenced a snooze mid meal.",
"truncated": False,
"display_text_range": [0, 79],
"entities": {"hashtags": [], "symbols": [], "following": True,
"follow_request_sent": False, "notifications": False,
"translator_type": "none"},
"geo": None, "coordinates": None,
"place": None,
"contributors": None,
"is_quote_status": False,
"retweet_count": 8964,
"favorite_count": 42908,
"favorited": False,
"retweeted": False,
"possibly_sensitive": False,
"possibly_sensitive_appealable": False,
"lang": "en"}]
To clean it you can use :
import json
new_list=[]
for i in range(len(tweet_list)):
new_list.append(json.loads(tweet_list[i]))
Then you can use :
import pandas as pd
df = pd. DataFrame. from_dict(new_list)
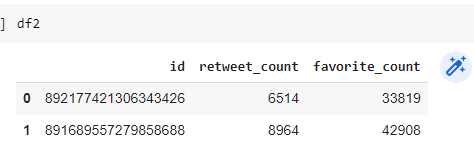
df2=pd.DataFrame(data=df[['id','retweet_count','favorite_count']])

CodePudding user response:
You have actually list of strs, which were created by serializing dicts using JSON (not false rather than False and null rather than None). Apply json.loads at them and then create DataFrame, consider following simple example
import json
import pandas as pd
data = ['{"A":1,"B":null}','{"A":null,"B":2}','{"A":null,"B":null}']
df = pd.DataFrame(map(json.loads,data))
print(df)
gives output
A B
0 1.0 NaN
1 NaN 2.0
2 NaN NaN
Explanation: I use map built-in function to apply json.loads to each element of list and then create pandas.DataFrame from them.