My CSV sample data is
ID,Project,From,To,Percentage
1,APPLE,01-01-2022,31-03-2022,50
1,MICROSOFT,01-01-2022,15-01-2022,50
1,MICROSOFT,01-02-2022,28-02-2022,50
1,MICROSOFT,01-03-2022,31-03-2022,50
2,ORACLE,01-02-2022,23-06-2022,50
3,APPLE,23-04-2022,23-06-2022,100
1,MICROSOFT,16-01-2022,31-01-2022,50
2,DELL,01-12-2021,01-04-2022,50
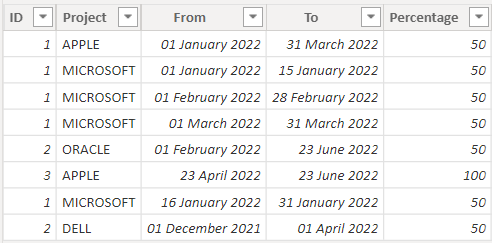
My objective is to see if on any date any employee has been allocated for more than 100% in a project. As you can see employee id 1 has been allocated 1/Jan/22 to 31/Mar/22 for 50% in APPLE and multiple sub-periods in MICROSOFT for 50% itself but it isn't for any period greater than 100% allocation.
How when I sum(percentage) using this criteria (StartA <= EndB) and (EndA >= StartB)
I get 250% for the first line item because it will match with all other line times for ID=1. The period is engulfing all the smaller periods.
Is there a way to check if any employee has been allocated for more than 100% on any given date?
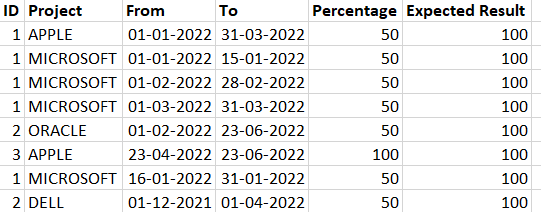
Edit: EXPECTED RESULT
CodePudding user response:
One of your problems is your expect result given your data would be rather lame. So I added one more line:
ID Project From To Percentage
0 1 APPLE 2022-01-01 2022-03-31 50
1 1 MICROSOFT 2022-01-01 2022-01-15 50
2 1 MICROSOFT 2022-02-01 2022-02-28 50
3 1 MICROSOFT 2022-03-01 2022-03-31 50
4 2 ORACLE 2022-02-01 2022-06-23 50
5 3 APPLE 2022-04-23 2022-06-23 100
6 1 MICROSOFT 2022-01-16 2022-01-31 50
7 2 DELL 2021-12-01 2022-04-01 50
0 1 Home 2022-01-01 2022-01-07 75
Doing:
# Format dates as proper datetimes.
df['From'] = pd.to_datetime(df['From'], format='%d-%m-%Y')
df['To'] = pd.to_datetime(df['To'], format='%d-%m-%Y')
# Create the date Range:
df['dates'] = df.apply(lambda row: pd.date_range(row.From, row.To, freq='D'), axis=1)
# Explode the dates:
df = df.explode('dates')
# Find the dates where someone is over allocated:
out = df.groupby(['ID', 'dates'])['Percentage'].sum()[lambda x: x.gt(100)]
print(out.reset_index())
Output:
ID dates Percentage
0 1 2022-01-01 175
1 1 2022-01-02 175
2 1 2022-01-03 175
3 1 2022-01-04 175
4 1 2022-01-05 175
5 1 2022-01-06 175
6 1 2022-01-07 175
To put it back into your original data format:
df['allocation'] = df.groupby(['ID', 'dates'])['Percentage'].transform('sum')
df = df.groupby(['ID', 'Project', 'From', 'To', 'Percentage'], as_index=False)['allocation'].max()
Output:
ID Project From To Percentage allocation
0 1 APPLE 2022-01-01 2022-03-31 50 175
1 1 Home 2022-01-01 2022-01-07 75 175
2 1 MICROSOFT 2022-01-01 2022-01-15 50 175
3 1 MICROSOFT 2022-01-16 2022-01-31 50 100
4 1 MICROSOFT 2022-02-01 2022-02-28 50 100
5 1 MICROSOFT 2022-03-01 2022-03-31 50 100
6 2 DELL 2021-12-01 2022-04-01 50 100
7 2 ORACLE 2022-02-01 2022-06-23 50 100
8 3 APPLE 2022-04-23 2022-06-23 100 100
CodePudding user response:
There may be no simple one-line code to do your task. However, it can be handled through some for loop and conditions as below:
import pandas as pd
import numpy as np
data = [{'id': 'ali', 'from': pd.Timestamp('2020-10-15'), 'to': pd.Timestamp('2020-10-17'),'Percentage':50},
{'id': 'ali', 'from': pd.Timestamp('2020-10-18'), 'to': pd.Timestamp('2020-10-22'),'Percentage':50},
{'id': 'ali', 'from': pd.Timestamp('2020-10-20'), 'to': pd.Timestamp('2020-10-25'),'Percentage':50},
{'id': 'sadegh', 'from': pd.Timestamp('2020-10-15'), 'to': pd.Timestamp('2020-10-17'), 'Percentage': 50},
{'id': 'sadegh', 'from': pd.Timestamp('2020-10-18'), 'to': pd.Timestamp('2020-10-22'), 'Percentage': 50},
{'id': 'sadegh', 'from': pd.Timestamp('2020-10-20'), 'to': pd.Timestamp('2020-10-25'), 'Percentage': 50}
]
df = pd.DataFrame.from_dict(data)
dic = {}
unique_times = np.unique(df['to'].to_list() df['from'].to_list())
list = []
for i in df.id.unique():
for count in range(unique_times.__len__()-1):
condition_1 = df[df.id==i]['from'] <= unique_times[count]
condition_2 = df[df.id==i]['to'] >= unique_times[count 1]
dic['{}_{}'.format(unique_times[count], unique_times[count 1])] = np.sum(df[df.id == i]['Percentage'][condition_1 & condition_2])
list.append(dic)
Data_frame = pd.DataFrame(list,index=df.id.unique())
In this code for each id, the percentage for each possible time interval is calculated and saved in a data frame. After that, You can simply determine if there is an interval of time for which the contribution percentage is higher than 100%.
CodePudding user response:
Calculate sum of percentage allocation by ID by individual date. Then take the max of each day by ID. In other words, sums the percentage on a day-by-day basis by ID then takes the max value over all the days:
pd.concat([df[['ID','Project','From','To']],df.apply(lambda x: pd.Series(x['Percentage'], index=pd.date_range(start=x['From'], end=x['To'])), axis=1)], axis=1) \
.groupby('ID').sum().max(axis=1)
ID
1 100.0
2 100.0
3 100.0
An example with a smaller set of date ranges
ID Project From To Percentage
0 1 APPLE 2022-01-01 2022-01-03 50
1 1 MICROSOFT 2022-01-01 2022-01-05 50
2 1 MICROSOFT 2022-01-02 2022-01-06 50
3 1 MICROSOFT 2022-01-06 2022-01-08 50
4 2 ORACLE 2022-01-01 2022-01-04 50
5 3 APPLE 2022-01-06 2022-01-08 100
6 1 MICROSOFT 2022-01-05 2022-01-08 50
7 2 DELL 2022-01-05 2022-01-08 50
pd.concat([df[['ID','Project','From','To']],df.apply(lambda x: pd.Series(x['Percentage'], index=pd.date_range(start=x['From'], end=x['To'])), axis=1)], axis=1) \
.groupby('ID').sum().max(axis=1)
ID
1 150.0
2 50.0
3 100.0
CodePudding user response:
where the employee is not 100% involved, will be NaN.
import numpy as np
import pandas as pd
aaa = df.groupby('ID').sum().reset_index()
mask = aaa[aaa['Percentage'] >= 100]
df.loc[np.isin(df['ID'], mask['ID']), 'expected result'] = 100
print(df)
Or you can do it easier and better. Take all the sums by ID, compare with the number 100 and get these indices. Assign 100 where the condition is met, and leave the remaining amounts as they are.
fff = df.groupby('ID')['Percentage'].transform('sum')
mask = fff.ge(100)
fff[mask] = 100
df['expected result'] = fff
print(df)