I have the following data shape and working BigQuery query:
WITH
Person AS (
SELECT 'Alice' AS name, 10 AS address_id,
[STRUCT("Rexi" AS name, 5 AS species_id), STRUCT("Luna", 6)] AS pets UNION ALL
SELECT 'Bob', 11, [STRUCT("Ralfie", 5)] UNION ALL
SELECT 'Chandra', 10, []),
Address AS (
SELECT 10 AS id, 'Jump Street' AS street, 'UK' AS country UNION ALL
SELECT 11, 'Paper Street', 'US'
),
Species AS (
SELECT 5 AS id, 'Dog' as name, 11 as lifespan UNION ALL
SELECT 6, 'Cat', 15
)
SELECT p.* EXCEPT (address_id),
(SELECT AS STRUCT a.* EXCEPT(id)) AS address
FROM Person p
JOIN Address a ON p.address_id = a.id
As we can see, Person has a pets array of records, and a joinable id with address. Each pet also has a joinable id with species.
Just like I've used SELECT p.* EXCEPT (address_id) to remove the address_id from my result and join address as a struct on each person, I wish I could remove the species_id field and join species as a struct on each pet.
i.e., I wish I had syntax like SELECT p.* EXCEPT (address_id, pets[*].species_id) and an ability to "join inside the struct".
My ideal result would be a query that doesn't have to repeat all species field names, but has results like this:
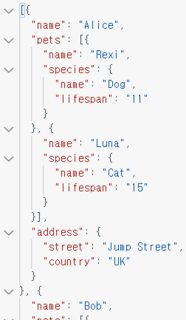
[{
"name": "Alice",
"pets": [{
"name": "Rexi",
"species": {
"name": "Dog",
"lifespan": 11,
}
}, {
"name": "Luna",
"species": {
"name": "Cat",
"lifespan": 15,
}
}],
"address": {
"street": "Jump Street",
"country": "UK"
}
},
<...>]
Is this possible somehow?
CodePudding user response:
As a followup answer of