I made a web scraper to get the informative text of a Wikipedia page. I get the text I want but I want to cut off a big part of the bottom text. I already tried some other solutions but with those, I don't get the headers and white-spaces I need.
import requests
from bs4 import BeautifulSoup
import re
website = "https://nl.wikipedia.org/wiki/Kat_(dier)"
request = requests.get(website)
soup = BeautifulSoup(request.text, "html.parser")
text = list()
text.extend(soup.findAll('mw-content-text'))
text_content = soup.text
text_content = re.sub(r'==.*?== ', '', text_content)
# text_content = text.replace('\n', '')
print(text_content)
Here, soup.text is all the text of the wikipedia page with the class='mw-content-text' printed as a string. This prints the overall text I need but I need to cut off the string where it starts showing the text of the sources. I already tried the replace method but it didn't do anything.
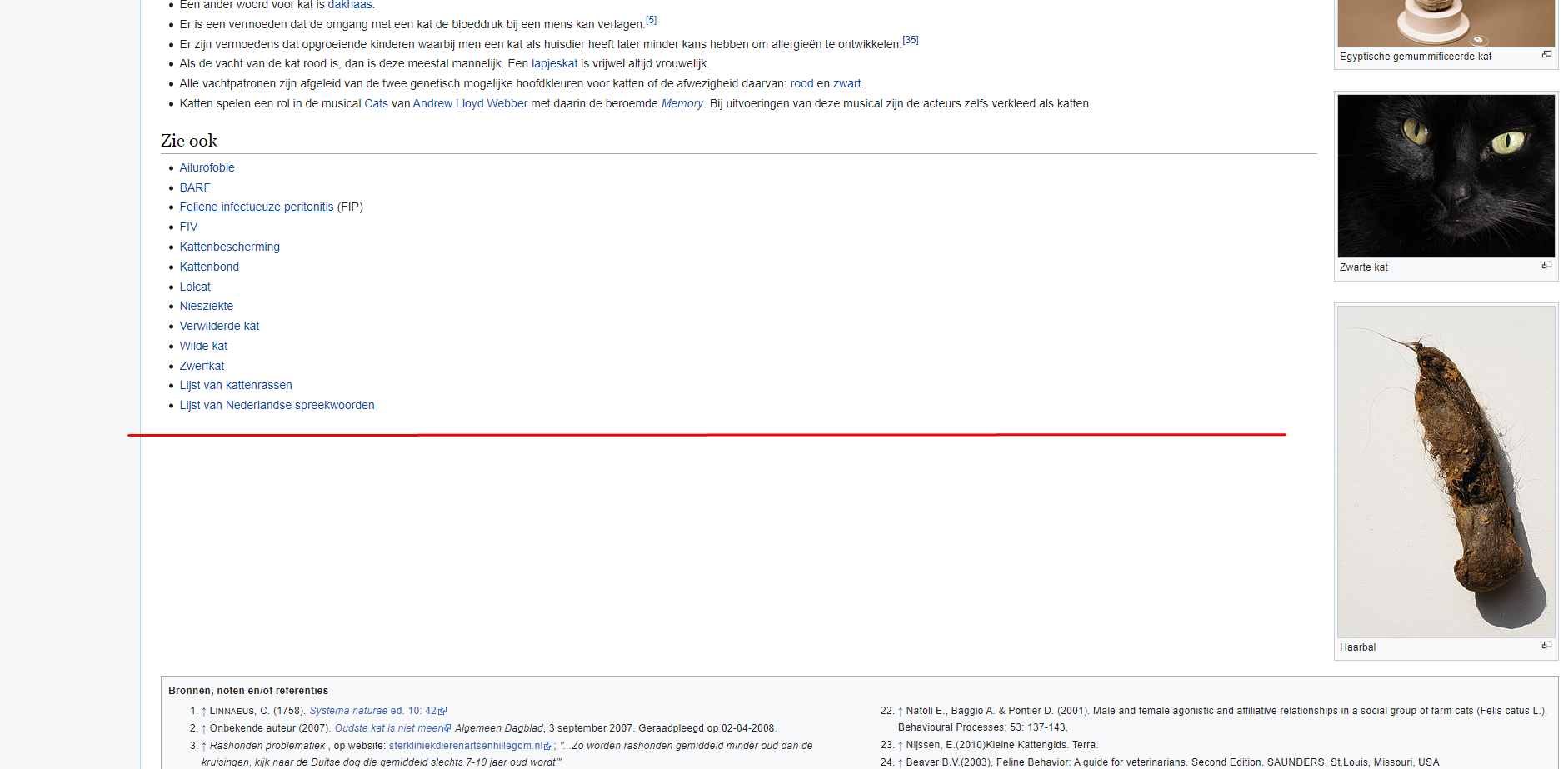
Given this page, I want to cut of what's under the red line in the big string of text I have scraped
I tried something like this, which didn't work:
for content in soup('span', {'class': 'mw-content-text'}):
print(content.text)
text = content.findAll('p', 'a')
for t in text:
print(text.text)```
I also tried this:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import requests
website = urlopen("https://nl.wikipedia.org/wiki/Kat_(dier)").read()
soup = BeautifulSoup(website,'lxml')
text = ''
for content in soup.find_all('p'):
text = content.text
text = re.sub(r'\[.*?\] ', '', text)
text = text.replace('\n', '')
# print(text)
but these approaches just gave me an unreadable mess of text. I still want the whitespaces and headers that my base code gives me.
CodePudding user response:
Think it is still a bit abstract but you could get your goal while iterating over all children and break if tag with class appendix appears:
for c in soup.select_one('#mw-content-text > div').find_all(recursive=False):
if c.get('class') and 'appendix' in c.get('class'):
break
print(c.get_text(strip=True))
Example
import requests
from bs4 import BeautifulSoup
website = "https://nl.wikipedia.org/wiki/Kat_(dier)"
request = requests.get(website)
soup = BeautifulSoup(request.text)
for c in soup.select_one('#mw-content-text > div').find_all(recursive=False):
if c.get('class') and 'appendix' in c.get('class'):
break
print(c.get_text(strip=True))
CodePudding user response:
There is likely a more efficient solution but here is a list comprehension that solves your issue:
# the rest of your code
references = [line for line in text_content.split('\n') if line.startswith("↑")]
Heres an alternative version that might be easier to understand:
# the rest of your code
# Turn text_content into a list of lines
text_content = text_content.split('\n')
references = []
# Iterate through each line and only save the values that start
# with the symbol used for each reference, on wikipedia: "↑"
# ( or "^" for english wikipedia pages )
for line in text_content:
if line.startswith("↑"):
references.append(line)
Both scripts will do the same thing.