I have a script that acts as a "test driver" (TD). That is, it drives test operations on a "system under test" (SUT). When I run my test framework script (tfs.sh) on my TD, it takes a SUT as an argument. The manual workflow looks like this:
TD ~ $ ./tfs.sh --sut=<IP of SUT>
I want to have a cluster of SUTs (they will have different OSes, and each will repeat a few times), and a few TDs (like, 4 or 5, so driving tests won't be a bottleneck, actually executing them will be).
I don't know the Jenkins primitive with which to accomplish this. I would like it if a Jenkins stage could simply be invoked with 2 agents. One would obviously be the TD, that's what would actually run the script. And the other would be the SUT. Jenkins would manage locking & resource contention like this.
As a workaround, I could simply have all my SUTs entirely unmanaged by Jenkins, and manually implement locking of the SUTs so 2 different TDs don't try to grab the same one. But why re-invent the wheel? And besides, I'd rather work on a Jenkins plugin to accomplish this than on a manual solution.
How can I run a single Jenkins stage on 2 (or more) agents?
CodePudding user response:
If I understand your requirement correctly, you have a static list of SUTs and you want Jenkins to start the TDs by allocating SUTs for each TD. I'm assuming TDs and SUTs have a one-to-one relationship. Following is a very simple example of how you can achieve what you need.
pipeline {
agent any
stages {
stage('parallel-run') {
steps {
script {
try {
def tests = getTestExecutionMap()
parallel tests
} catch (e) {
currentBuild.result = "FAILURE"
}
}
}
}
}
}
def getTestExecutionMap() {
def tests = [:]
def sutList = ["IP1", "IP2" , "IP3"]
int count = 0
for(String ip : sutList) {
tests["TEST${count}"] = {
node {
stage("TD with SUT ${ip}") {
script {
sh "./tfs.sh --sut=${ip}"
}
}
}
}
count
}
return tests
}
The above pipeline will result in the following.
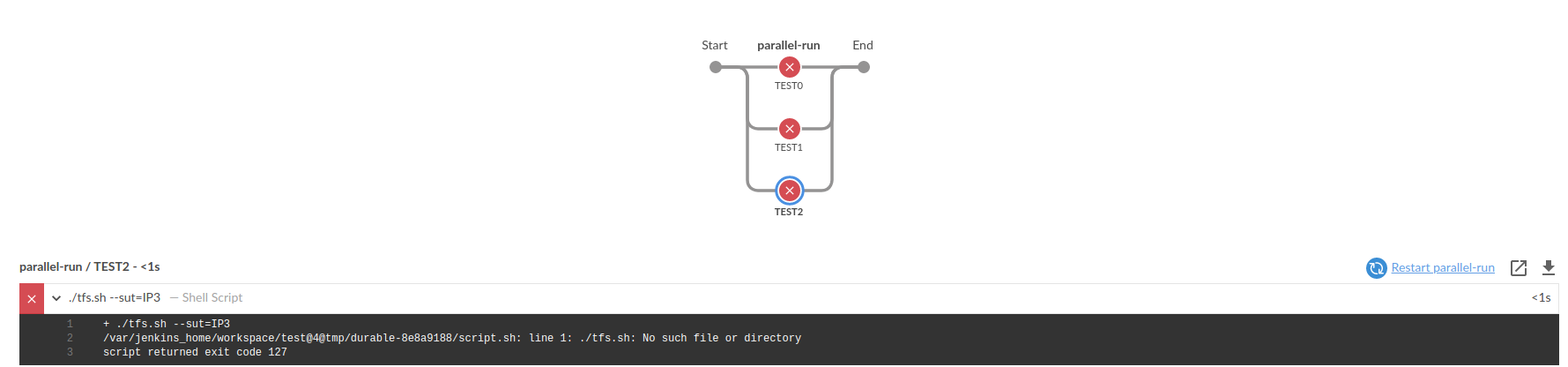
Further if you wan to select the agent you want to run the TD. You can specify the name of the agent in the node block. node(NAME) {...} . You can improve the Agent selection criteria accordingly. For example you can check how many Jenkins executors are idling for a given Agent and then decide how many TDs you will start there.
CodePudding user response:
Do you strictly need agents? Could you alternatively use lockable resources?
lock(label: 'some_resource', variable: 'LOCKED_RESOURCE', quantity: 2) {
// comma separated names of all acquired locks
echo env.LOCKED_RESOURCE
// first lock
echo env.LOCKED_RESOURCE0
// second lock
echo env.LOCKED_RESOURCE1
}
Have you considered Declarative Matrix?
matrix {
axes {
axis {
name 'PLATFORM'
values 'linux', 'mac', 'windows'
}
}
stages {
stage('build') {
// ...
}
stage('test') {
// ...
}
stage('deploy') {
// ...
}
}
}