I am currently working on visualizing formula one standings using the 'ergast' API in R using jsonlite. I have gathered data from all f1 standings since 1950 and cleaned up the data as shown in the picture of the dataset. I have already cumulated the data to determine for every year how many seasons the given driver has won. I now want to transform the dataset in a way that I have for every year, and for every driver, the cum_seasons_won so, e.g., in the first row or the first season (1950), cum_seasons_won should be for every driver in the dataset (except Nino Farina) 0. Another example would be in the last row: there should still be a value for, i.e., Juan Fangio with the value of five since he has won 5 championships to this day.
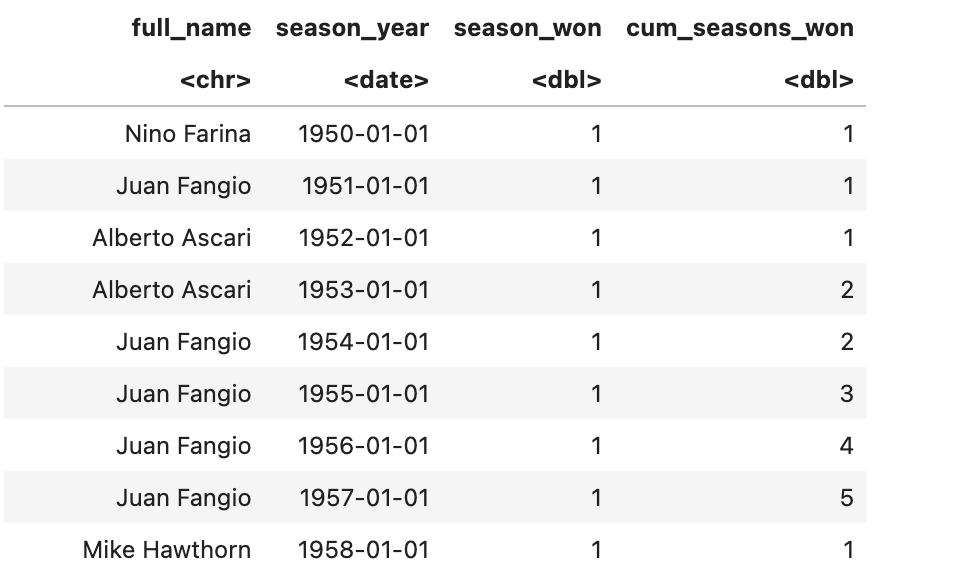
Any Help is greatly appreciated. Also, dplyr solutions and syntax would be preferred, but everything that gets me on the right track is helpful.
(Excuse the title, I don't know what the transformation I need to perform is called)
This is the dput output to reproduce the dataset:
structure(list(full_name = c("Nino Farina", "Juan Fangio", "Alberto Ascari",
"Alberto Ascari", "Juan Fangio", "Juan Fangio"), season_year = structure(c(-7305,
-6940, -6575, -6209, -5844, -5479), class = "Date"), season_won = c(1,
1, 1, 1, 1, 1), cum_seasons_won = c(1, 1, 1, 2, 2, 3)), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"), row.names = c(NA, -6L), groups = structure(list(
full_name = c("Alberto Ascari", "Juan Fangio", "Nino Farina"
), .rows = structure(list(3:4, c(2L, 5L, 6L), 1L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -3L), .drop = TRUE))
CodePudding user response:
example data
df <- data.frame(name = c("Nino","Juan","Alberto","Alberto","Juan"),
year = 1950:1954,
season_won = rep(1,5))
Result:
name year season_won
1 Nino 1950 1
2 Juan 1951 1
3 Alberto 1952 1
4 Alberto 1953 1
5 Juan 1954 1
calculate cumulative wins
library(dplyr)
# for each driver, calculate cumulative win sums
df %>%
group_by(name) %>%
mutate(cum_seasons_won = row_number()) %>% # or: cum_seasons_won = cumsum(season_won)
ungroup()
Result:
# A tibble: 5 × 4
name year season_won cum_seasons_won
<chr> <int> <dbl> <int>
1 Nino 1950 1 1
2 Juan 1951 1 1
3 Alberto 1952 1 1
4 Alberto 1953 1 2
5 Juan 1954 1 2
calculate cumulative wins ánd add rows to complete all years for all drivers
Since you've asked for this in the title of the question:
library(dplyr)
library(tidyr)
df %>%
# create missing rows, set season_won = 0
complete(name, year, fill=list(season_won=0)) %>%
# for each driver, calculate cumulative win sums
group_by(name) %>%
mutate(cum_seasons_won = cumsum(season_won)) %>%
ungroup() %>%
# optional: order by year, driver
arrange(year, name)
Result:
# A tibble: 15 × 4
name year season_won cum_seasons_won
<chr> <int> <dbl> <dbl>
1 Alberto 1950 0 0
2 Juan 1950 0 0
3 Nino 1950 1 1
4 Alberto 1951 0 0
5 Juan 1951 1 1
6 Nino 1951 0 1
7 Alberto 1952 1 1
8 Juan 1952 0 1
9 Nino 1952 0 1
[...]