I have a dataframe which looks like below,

Here is the same data in table format which you can copy/paste,
SourceName SourceType Edge TargetName TargetType
cardiac myosin DISEASE induce myocarditis DISEASE
cardiac myosin DISEASE induce heart disease DISEASE
nitric CHEMICAL inhibit chrysin CHEMICAL
peptide magainin CHEMICAL exhibited tumor DISEASE
Here is the same data in dictionary format which you can copy/paste,
{'id': [1, 2, 3, 4],
'SourceName': ['cardiac myosin',
'cardiac myosin',
'nitric',
'peptide magainin'],
'SourceType': ['DISEASE', 'DISEASE', 'CHEMICAL', 'CHEMICAL'],
'Edge': ['induce', 'induce', 'inhibit', 'exhibited'],
'TargetName': ['myocarditis',
'heart disease',
'chrysin',
'tumor'],
'TargetType': ['DISEASE', 'DISEASE', 'CHEMICAL', 'DISEASE']}
I tried using below code, but some of the SourceName was having wrong type, eg 'peptide magainin' should be a CHEMICAL, but it comes under DISEASE which is incorrect.
df1 = df.groupby(["id","SourceType","TargetType"])['SourceName', 'Edge', 'TargetName'].aggregate(lambda x: x).unstack().reset_index()
df1.columns=df1.columns.tolist()
Sample output which is incorrect, can someone help me with this, thanks.
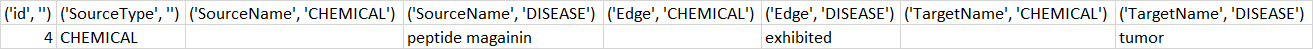
Expected output:

CodePudding user response:
I don't understand exactly what you try to achieve with the new structure, but it can be done by grouping once by "SourceType" and once by "TargetType", then merging the resulting dataframes:
source_df = pd.DataFrame()
target_df = pd.DataFrame()
for s, sub_df in df.groupby('SourceType'):
source_sub_df = sub_df[['id', 'SourceName']]
source_sub_df.columns = ['id', f'SourceType_{s}']
source_df = pd.concat([source_df, source_sub_df])
for t, sub_df in df.groupby('TargetType'):
target_sub_df = sub_df[['id', 'Edge', 'TargetName']]
target_sub_df.columns = ['id', 'Edge', f'TargetType_{t}']
target_df = pd.concat([target_df, target_sub_df])
df_out = source_df.merge(target_df, on='id').sort_values('id').reset_index(drop=True)
print(df_out)
Output:
id SourceType_CHEMICAL SourceType_DISEASE Edge TargetType_CHEMICAL TargetType_DISEASE
0 1 NaN cardiac myosin induce NaN myocarditis
1 2 NaN cardiac myosin induce NaN heart disease
2 3 nitric NaN inhibit chrysin NaN
3 4 peptide magainin NaN exhibited NaN tumor