There are many similar questions and answers already posted but I could not find one with these differences. 1) The count of NULLs starts over, and 2) there is a math function applied to the replaced value.
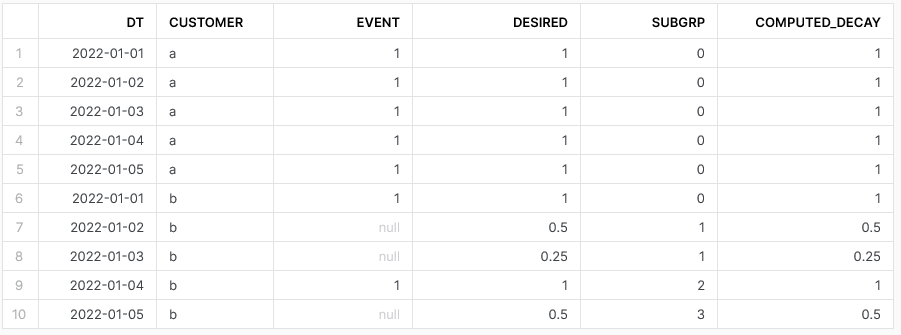
An event either takes place or not (NULL or 1), by date by customer. Can assume that a customer has one and only one row for every date.
I want to replace the NULLs with a decay function based on number of consecutive NULLs (time from event). A customer can have the event every day, skip a day, skip multiple days. But once the event takes place, the decay starts over. Currently my decay is divide by 2 but that is for example.
| DT | CUSTOMER | EVENT | DESIRED |
|---|---|---|---|
| 2022-01-01 | a | 1 | 1 |
| 2022-01-02 | a | 1 | 1 |
| 2022-01-03 | a | 1 | 1 |
| 2022-01-04 | a | 1 | 1 |
| 2022-01-05 | a | 1 | 1 |
| 2022-01-01 | b | 1 | 1 |
| 2022-01-02 | b | 0.5 | |
| 2022-01-03 | b | 0.25 | |
| 2022-01-04 | b | 1 | 1 |
| 2022-01-05 | b | 0.5 |
I can produce the desired result, but it is very unwieldy. Looking if there is a better way. This will need to be extended for multiple event columns.
create or replace temporary table the_data (
dt date,
customer char(10),
event int,
desired float)
;
insert into the_data values ('2022-01-01', 'a', 1, 1);
insert into the_data values ('2022-01-02', 'a', 1, 1);
insert into the_data values ('2022-01-03', 'a', 1, 1);
insert into the_data values ('2022-01-04', 'a', 1, 1);
insert into the_data values ('2022-01-05', 'a', 1, 1);
insert into the_data values ('2022-01-01', 'b', 1, 1);
insert into the_data values ('2022-01-02', 'b', NULL, 0.5);
insert into the_data values ('2022-01-03', 'b', NULL, 0.25);
insert into the_data values ('2022-01-04', 'b', 1, 1);
insert into the_data values ('2022-01-05', 'b', NULL, 0.5);
with
base as (
select * from the_data
),
find_nan as (
select *, case when event is null then 1 else 0 end as event_is_nan from base
),
find_nan_diff as (
select *, event_is_nan - coalesce(lag(event_is_nan) over (partition by customer order by dt), 0) as event_is_nan_diff from find_nan
),
find_nan_group as (
select *, sum(case when event_is_nan_diff = -1 then 1 else 0 end) over (partition by customer order by dt) as nan_group from find_nan_diff
),
consec_nans as (
select *, sum(event_is_nan) over (partition by customer, nan_group order by dt) as n_consec_nans from find_nan_group
),
decay as (
select *, case when n_consec_nans > 0 then 0.5 / n_consec_nans else 1 end as decay_factor from consec_nans
),
ffill as (
select *, first_value(event) over (partition by customer order by dt) as ffill_value from decay
),
final as (
select *, ffill_value * decay_factor as the_answer from ffill
)
select * from final
order by customer, dt
;
Thanks
CodePudding user response:
The query could be simplified by using