I'm trying to write a functional code that will read data from multiple excel sheets, carry out some calculations, and then append a summary to the bottom of data in the excel sheet where the data was read from.
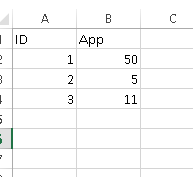
An example excel sheet data or data frame:
ID APP
1 20
2 50
3 79
4 34
5 7
6 5
7 3
8 78
Required output: summary output starts 2 rows below the original data as below
ID APP
1 20
2 50
3 79
4 34
5 7
6 5
7 3
8 78
Sumary:
Total=276
My attempt:
import pandas as pd
from excel import append_df_to_excel
path = 'data.xlsx'
Exls = pd.ExcelFile(path, engine='openpyxl')
for sheet in Exls.sheet_names:
try:
df = pd.read_excel(Exls,sheet_name=sheet)
res=df.groupby['App'].sum
writer = pd.ExcelWriter('data.xlsx', engine='xlsxwriter')
df.to_excel(writer, res, sheet_name='Sheet1', startrow = 1, index=False)
workbook = writer.book
worksheet = writer.sheets[data']
text = 'summary'
worksheet.write(0, 0, text)
writer.save()
except Exception:
continue
This code does not append any result to the excel file. Has anyone got better ideas?
CodePudding user response:
The try..catch is the reason your sheet isn't updating. You have a few bugs in your code that are silently passing (the casing in the APP column does not match the spreadsheet, the groupby statement is malformed, you're missing an open quote on 'data', you're trying to write the summary to the top of the sheet instead of the bottom). Those are easy enough to patch up, though, your biggest issue is that you're trying to open an already-open file (actually, you try to open and close it for each sheet).
So what you're going to want to do is move the file operations outside the for-loop, and try to just have one file open and one file save. You can get a lot more concise that way like this:
import pandas as pd
path = 'data.xlsx'
xl = pd.ExcelFile(path)
writer = pd.ExcelWriter(xl, engine='openpyxl', mode='a')
workbook = writer.book
for worksheet in workbook.worksheets:
sheet_name = worksheet.title
df = xl.parse(sheet_name=sheet_name)
sheet_end = len(df) 2
total = df.APP.sum()
worksheet[f'A{sheet_end}'] = 'Summary:'
worksheet[f'A{sheet_end 1}'] = f'total={total}'
writer.save()
CodePudding user response:
Use:
import pandas as pd
xl = pd.ExcelFile('01.xlsx')
sheets = xl.sheet_names
writer = pd.ExcelWriter('output1.xlsx')
for sheet in sheets:
df = pd.read_excel('01.xlsx', sheet_name=sheet)
sum_ = pd.DataFrame({'ID': ['Summary:'], 'App': [df['App'].sum()]})
df = df.append(sum_, ignore_index=True)
df.to_excel(writer, sheet_name=sheet, index=False)
writer.save()
writer.close()
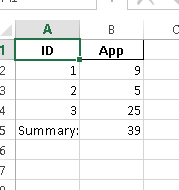
Note that 01.xlsx is a file with some sheets similar to the following image, and the output1.xlsx is the output file.