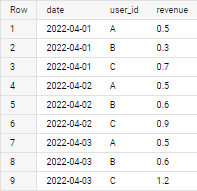
I have a table that includes users that created an event in the app and they produced some revenue based on this event (it's added cummulatively every day):
| date | user_id | revenue |
|---|---|---|
| 2022-04-01 | A | 0.5 |
| 2022-04-01 | B | 0.3 |
| 2022-04-01 | C | 0.7 |
| 2022-04-02 | B | 0.6 |
| 2022-04-02 | C | 0.9 |
| 2022-04-03 | C | 1.2 |
What I want to do is use the data about all the users from the first day, but if they don't bring any revenue, I would like to use the revenue value for this user from the previous day, like so:
| date | user_id | revenue |
|---|---|---|
| 2022-04-01 | A | 0.5 |
| 2022-04-01 | B | 0.3 |
| 2022-04-01 | C | 0.7 |
| 2022-04-02 | A | 0.5 |
| 2022-04-02 | B | 0.6 |
| 2022-04-02 | C | 0.9 |
| 2022-04-03 | A | 0.5 |
| 2022-04-03 | B | 0.6 |
| 2022-04-03 | C | 1.2 |
My initial idea was to somehow copy first day user_id's and leave the revenue value for this day as null:
| date | user_id | revenue |
|---|---|---|
| 2022-04-01 | A | 0.5 |
| 2022-04-01 | B | 0.3 |
| 2022-04-01 | C | 0.7 |
| 2022-04-02 | A | null |
| 2022-04-02 | B | 0.6 |
| 2022-04-02 | C | 0.9 |
| 2022-04-03 | A | null |
| 2022-04-03 | B | null |
| 2022-04-03 | C | 1.2 |
Then I would use this to find the right values to fill NULLs with
SELECT date,
user_id,
revenue,
LAST_VALUE(revenue, IGNORE NULLS) as last_values
FROM table
So the question is, how do I go about "copying" my first day users to every following day in the table? Maybe, there is a better solution than the one I've thought about?
CodePudding user response:
The problem of this task is generating an output that contains the cartesian product of "user_id" values with "date" values. One option is to generate the empty cartesian product first, then LEFT JOIN with your original table and fill the NULL values using a window function.
Instead of the LAST_VALUE function, you could use the MAX window function and limit its frame till the current row. Given that your revenue values are cumulative, you should get exactly the last non-null value as a correct output.
WITH cte AS (
SELECT *
FROM (SELECT DISTINCT date FROM tab) dates
INNER JOIN (SELECT DISTINCT user_id FROM tab) users
ON 1=1
)
SELECT cte.user_id,
cte.date,
COALESCE(tab.revenue,
MAX(revenue) OVER(PARTITION BY user_id
ORDER BY date
ROWS UNBOUNDED PRECEDING)) AS revenue
FROM cte
LEFT JOIN tab
ON cte.user_id = tab.user_id
AND cte.date = tab.date
ORDER BY cte.user_id,
cte.date
CodePudding user response:
Consider below approach
select date, user_id,
first_value(revenue ignore nulls) over prev_values as revenue
from (select distinct date from your_table),
(select distinct user_id from your_table)
left join your_table
using(date, user_id)
window prev_values as (
partition by user_id order by date desc
rows between current row and unbounded following
)
order by date, user_id
if applied to sample data in y our question - output is