I have a list sub = ["A","B","C","D","E","F"] and a dataframe of the following format:
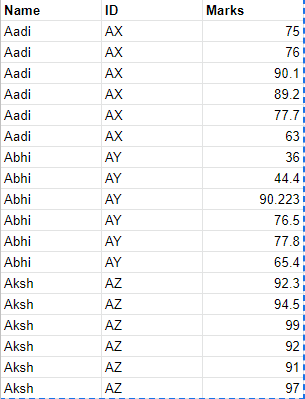
I need to write a code for my dataframe to finally look like the following format:
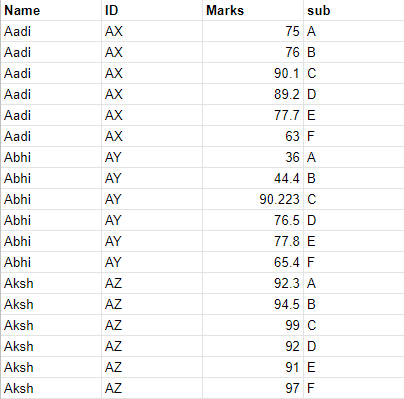
CodePudding user response:
You can use numpy.tile and repeat elements base len(df) and len(sub) then use pandas.assign for creating dataframe.
import numpy as np
sub = ["A","B","C","D","E","F"]
sub = np.asarray(sub)
# If len(df)/len(sub)) is an integer number
df = df.assign(sub = np.tile(sub, int(len(df)/len(sub))))
# If len(df) not divide by len(sub) and have reminder
df = df.assign(sub = np.tile(sub, len(df))[:len(df)])
Check:
df = pd.DataFrame(
{
"col1": np.random.randint(0, 10, size=(13,)),
"col2": np.random.randint(100, 1000, size=(13,)),
}
)
print(df)
Output:
col1 col2 sub
0 4 608 A
1 7 432 B
2 1 978 C
3 8 155 D
4 8 863 E
5 7 589 F
6 5 649 A
7 0 726 B
8 7 269 C
9 6 792 D
10 9 437 E
11 0 989 F
12 0 854 A
CodePudding user response:
You can create a cycle using itertools.cycle, and cut it to the appropriate length using itertools.islice.
>>> from itertools import cycle, islice
...
... cycle_list = ["A", "B", "C", "D", "E", "F"]
...
... list(islice(cycle(cycle_list), 13))
['A', 'B', 'C', 'D', 'E', 'F', 'A', 'B', 'C', 'D', 'E', 'F', 'A']
So, in your case, you can just cut it to the length of the dataframe and assign it as a new column:
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
"col1": np.random.randint(0, 10, size=(13,)),
"col2": np.random.randint(100, 1000, size=(13,)),
}
)
df["col3"] = list(islice(cycle(cycle_list), len(df)))
which gives:
col1 col2 col3
0 8 413 A
1 1 590 B
2 8 508 C
3 3 147 D
4 1 821 E
5 5 757 F
6 2 857 A
7 5 644 B
8 4 536 C
9 9 959 D
10 0 769 E
11 0 943 F
12 7 276 A