I would like to extract the information from this website: 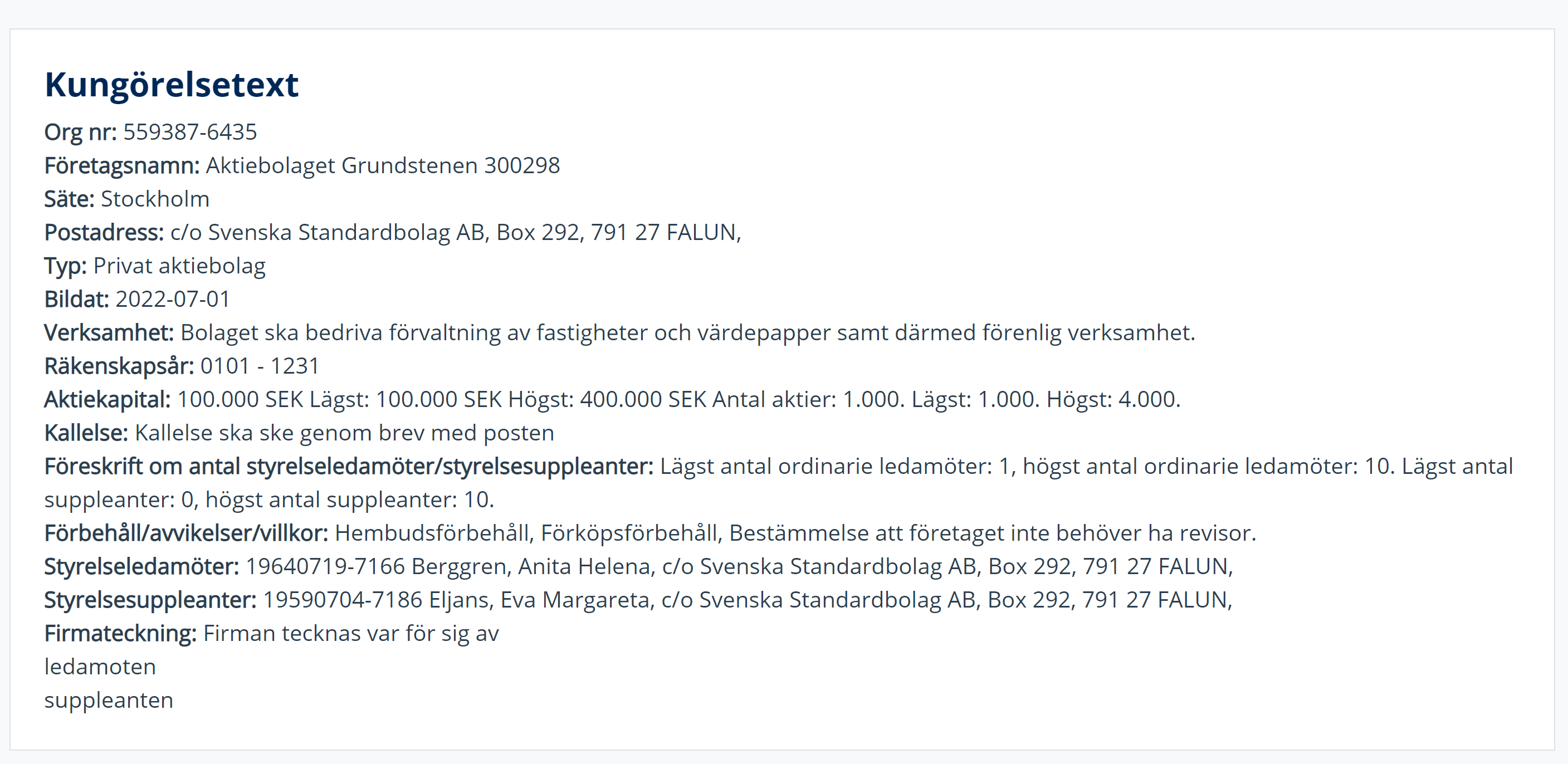
But the problem is that this website requires javascript.
I am not sure how to go about extracting this information and it seems that this info is not part of the source code.
What I would like to do is to put the information into a list like this:
[{ orgnr:559387-6435, företagsnamn:Aktiebolaget Grundstenen 300298, säte:Stockholm, etc. }, { orgnr:4389483439, företagsnamn:Some other name, säte:some city, etc. }]
I get this link and a several other links from a list I create in an earlier step
[link1:https....,link2:https...,link3:https...]
I have tried to use selenium but I cannot get past the step of opening Firefox. I am running python 3.10 on Windows 11.
Thank you all in advance!
CodePudding user response:
The data comes from a xhr/fetch. You can find it here: https://poit.bolagsverket.se/poit/rest/HamtaKungorelse?kungorelseid=K397881/22
CodePudding user response:
I do not know Selenium, but alternatively you could try the requests-html module for python to render the javascript. From the requests-html documentation:
r = session.get('http://python-requests.org')
r.html.render()
After that, BeautifulSoup can help you parse the contents.