I have some HTML pages that I am trying to extract the text from using asynchronous web requests through aiohttp and asyncio, after extracting them I save the files locally. I am using BeautifulSoup(under extract_text()), to process the text from the response and extract the relevant text within the HTML page(exclude the code, etc.) but facing an issue where my synchronous version of the script is faster than my asynchronous multiprocessing.
As I understand, using the BeautifulSoup function causes the main event loop to block within parse(), so based on these two StackOverflow questions[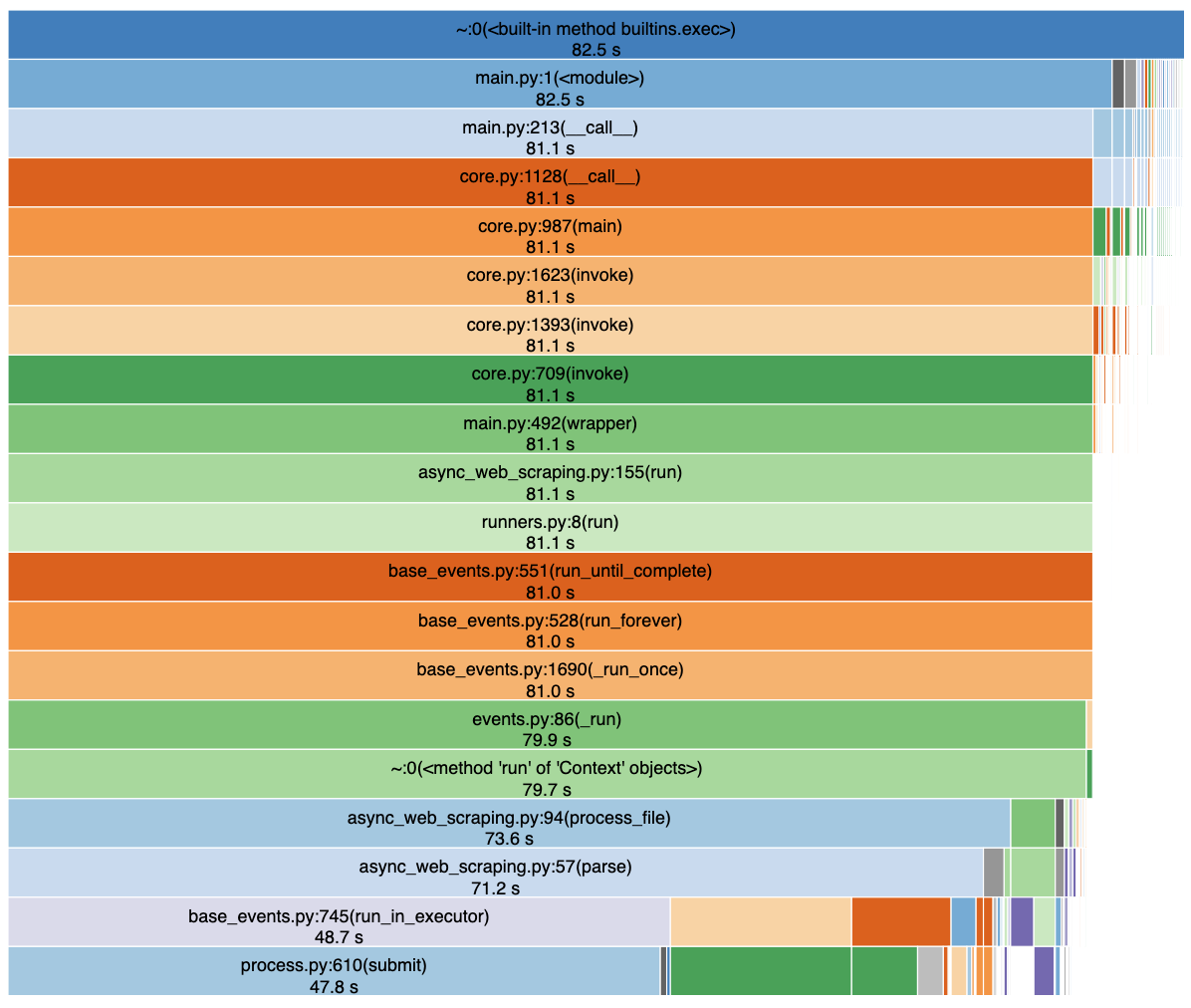
- Async version without extract_text
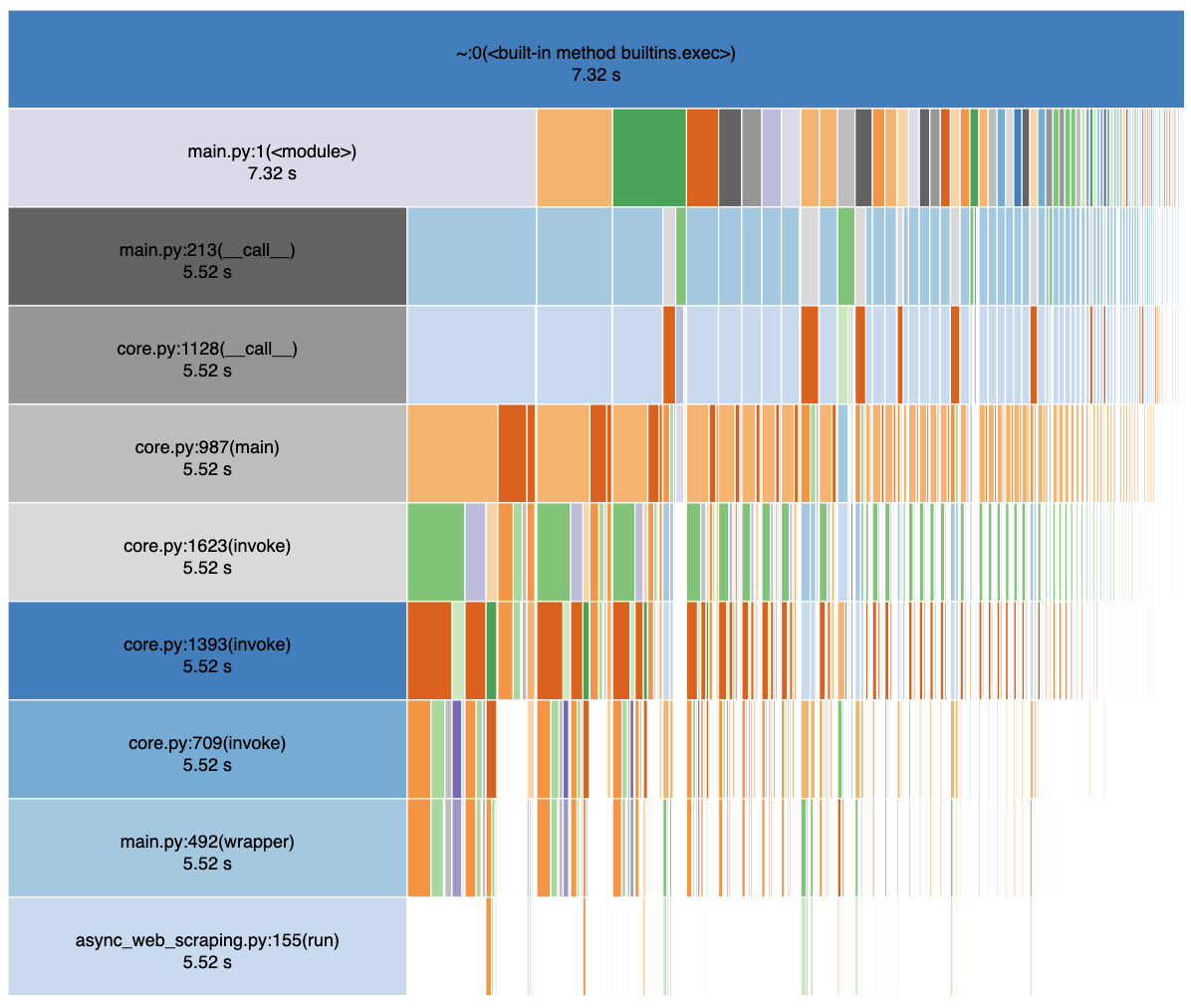
- Sync version with extract_text(notice how the html_parser from BeautifulSoup takes up the majority of the time here)
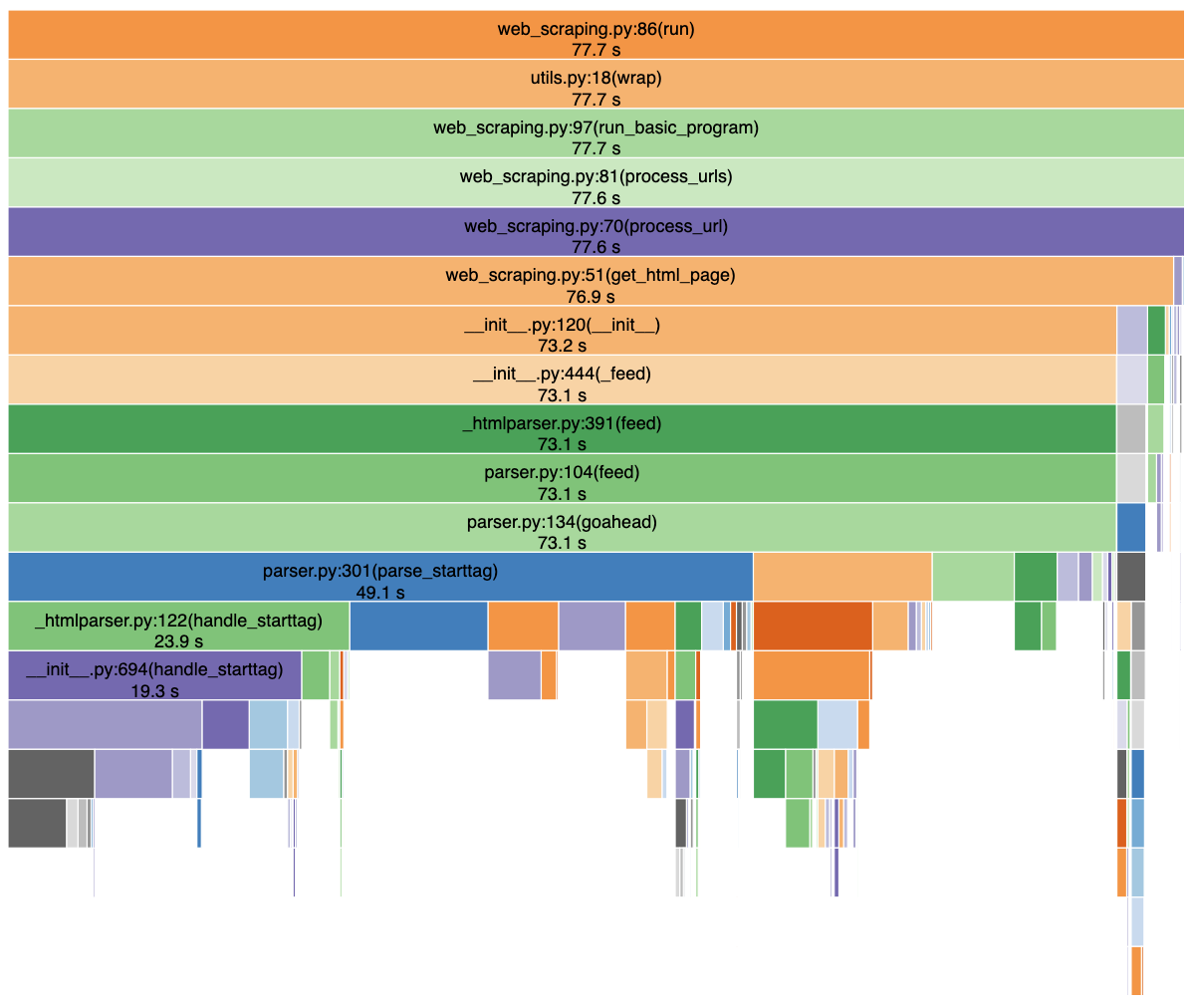
- Sync version without extract_text
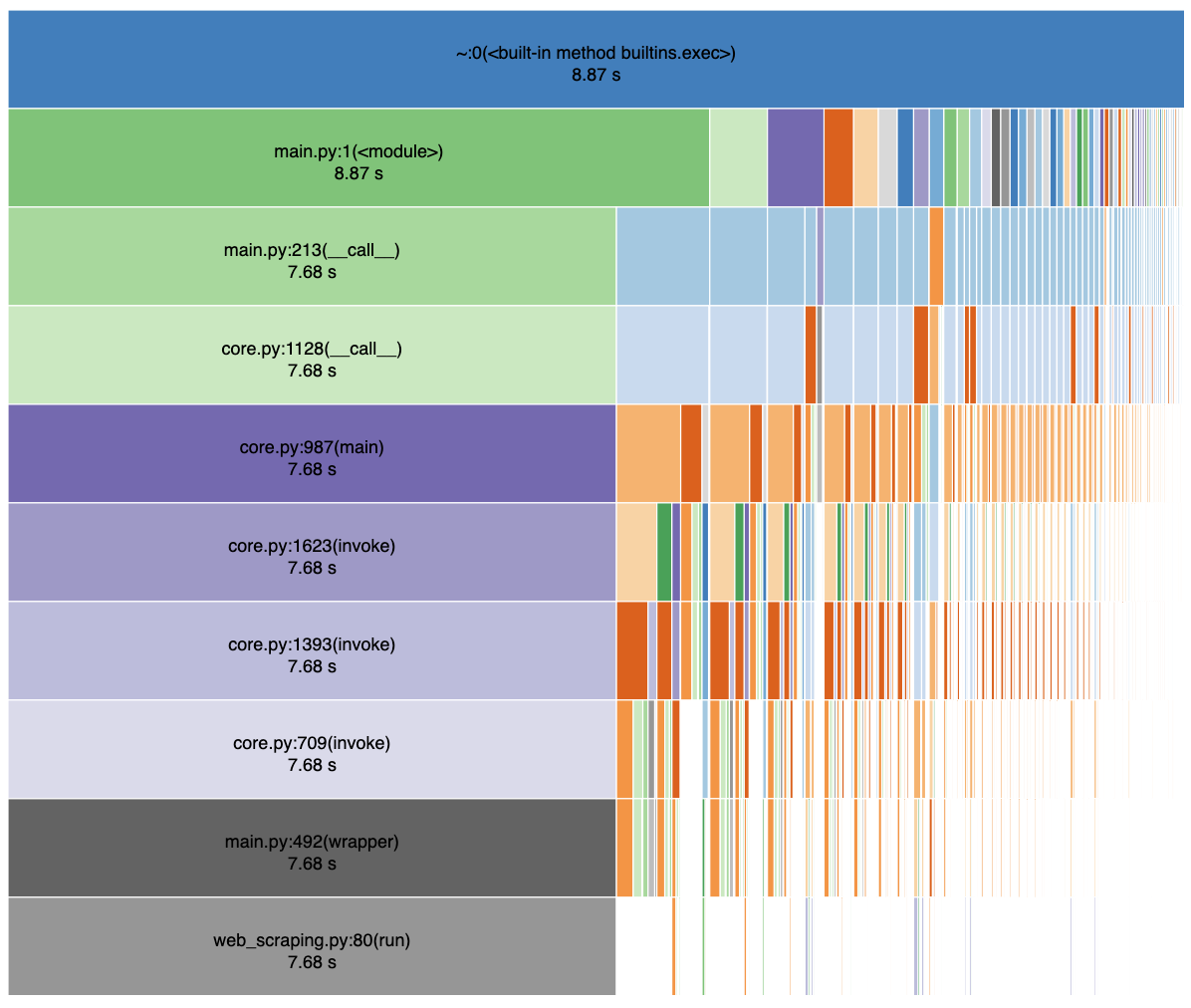
CodePudding user response:
Here is roughly what your asynchronous program does:
- Launch
num_filesparse()tasks concurrently - Each
parse()task creates its ownProcessPoolExecutorand asynchronously awaits forextract_text(which is executed in the previously created process pool).
This is suboptimal for several reasons:
- It creates
num_filesprocess pools, which are expensive to create and takes memory - Each pool is only used for one single operation, which is counterproductive: as many concurrent operations as possible should be submitted to a given pool
You are creating a new ProcessPoolExecutor each time the parse() function is called. You could try to instantiate it once (as a global for instance, of passed through a function argument):
from concurrent.futures import ProcessPoolExecutor
async def parse(loop, executor, ...):
...
text = await loop.run_in_executor(executor, extract_text)
# and then in `process_file` (or `process_files`):
async def process_file(...):
...
loop = asyncio.get_running_loop()
with ProcessPoolExecutor() as executor:
...
await process(loop, executor, ...)
I benchmarked the overhead of creating a ProcessPoolExecutor on my old MacBook Air 2015 and it shows that it is quite slow (almost 100 ms for pool creation, opening, submit and shutdown):
from time import perf_counter
from concurrent.futures import ProcessPoolExecutor
def main_1():
"""Pool crated once"""
reps = 100
t1 = perf_counter()
with ProcessPoolExecutor() as executor:
for _ in range(reps):
executor.submit(lambda: None)
t2 = perf_counter()
print(f"{(t2 - t1) / reps * 1_000} ms") # 2 ms/it
def main_2():
"""Pool created at each iteration"""
reps = 100
t1 = perf_counter()
for _ in range(reps):
with ProcessPoolExecutor() as executor:
executor.submit(lambda: None)
t2 = perf_counter()
print(f"{(t2 - t1) / reps * 1_000} ms") # 100 ms/it
if __name__ == "__main__":
main_1()
main_2()
You may again hoist it up in the process_files function, which avoid recreating the pool for each file.
Also, try to inspect more closely your first SnakeViz chart in order to know what exactly in process.py:submit is taking that much time.
One last thing, be careful of the semantics of using a context manager on an executor:
from concurrent.futures import ProcessPoolExecutor
with ProcessPoolExecutor() as executor:
for i in range(100):
executor.submit(some_work, i)
Not only this creates and executor and submit work to it but it also waits for all work to finish before exiting the with statement.