I'm streaming data from kafka and trying to merge ~30 million records to delta lake table.
def do_the_merge(microBatchDF, partition):
deltaTable.alias("target")\
.merge(microBatchDF.alias("source"), "source.id1= target.id2 and source.id= target.id")\
.whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
I see that spark is stuck on task for almost an hour on the task named SynapseLoggingShim
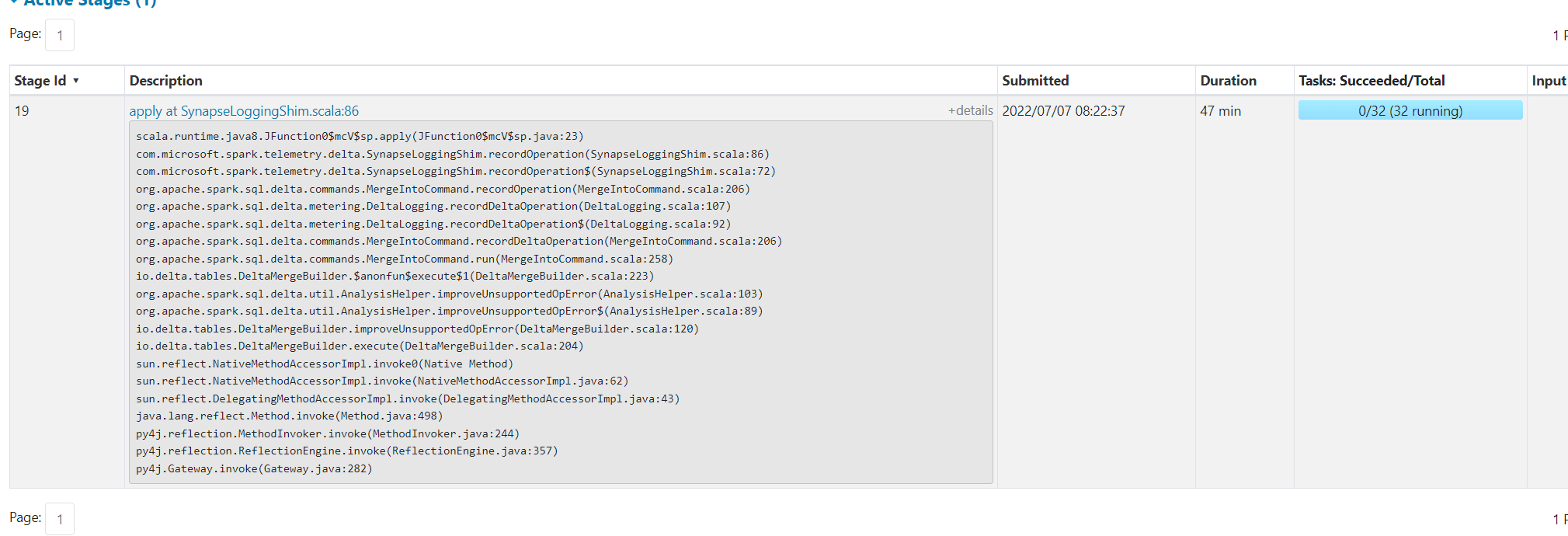
once this stage completes, then writing to delta table actually starts and takes one more
I'm trying to understand what this SynapseLoggingShim stage does ?
CodePudding user response:
Answering question myself, the synapseLoggingShim scala was waiting on the merge task to complete. It's just a open telemetry wrapper to collect the metrics.
The problem is , we are bottlenecked by the source ! The event hub that we are reading has 32 partitions and spark parallelism is constrained the event hub partitions. In simple words, increasing the spark cores doesn't help in decreasing the time as the source event hub limits the parallelism as per the topic partition count.